2026-06-29 Daily
🧠 今天记录
- 现有 flagcx 代码在空闲 cpu case 下虽然ttft 文档,但是确实存在与 old flagcx 相同参数下 ttft 会大 300ms ✅ 2026-06-29 旧 /workspace/liuda/pd_disaggregation/mooncake_conn/vllm-plugin/test-1-old-flagcx.log 新 /workspace/liuda/pd_disaggregation/mooncake_conn/vllm-plugin/test-1-new-flagcx.log 回归了三个改动(待画图)后发现 tebench 里面指定 64k 切分也会降低 latency
改之前:
最终tebench性能为:
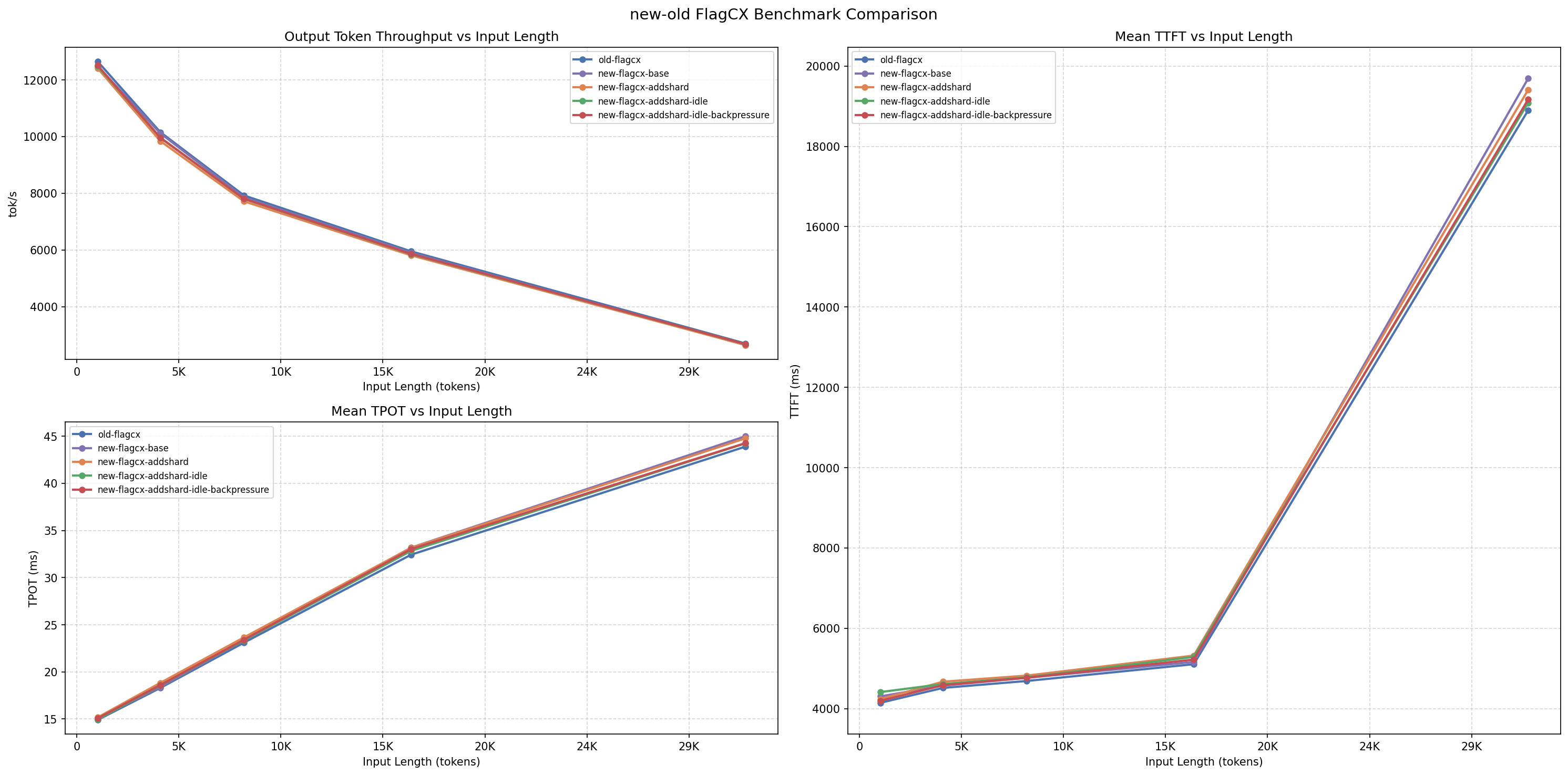
🚀 今日TODO
- 对 https://github.com/flagos-ai/FlagCX/pull/504 内的代码消融了改动,分析为什么(tebench 不太需要 shard 分组再分给多个线程, 端到端 pd 分离需要多个 shard,因为 p2pengine 按照 shard 提供多线程资源)会出现 latency 降低反而 ttft 增加 https://infrawaves.feishu.cn/wiki/ZDlTwcP8TiIvE5kXPErcvhyMnTf ,解决问题后已经合入。 ✅ 2026-06-29
- [ ]
🧩 遇到的问题 / 卡点
- [ ]
📌 明天该干啥
- [ ]