1. Overall
直接完成sender内存的数据到receiver内存的传输。无需中间 RecvFifo 干预。
- 在enqueue.cc内
ncclLaunchKernel内,符合下面三个条件:ncclPassSM,intraNode transfer和ipcRegistered[dir]==1就直接把sendbuff数据cudaMemcpyAsync到receiver的recvbuff内。 - transfer之前
cudaMemcpyAync需要拿到recvbuff地址,这里需要自己有一个mmap能够找到peer对的sendbuff和recvbuff。 - 完成transfer之后,下一个相同的
hostProxySyncCallback告诉我proxy的progress。sender的progress一直在轮询,sender负责告诉receiver当前copy完成,就直接退出,不减opCount。receiver的progress负责看当前是否完成,完成就减一个double args→nsubs的opCount数。双方的fn通过p2pShmProxyInfo内的新字段来看是否完成。Transclude of Zerocopy-p2p-design-2025-08-01-13.52.41.excalidraw
2. 具体方案
2.1 传递ipcRegistered
2.2 数初始化
- 在comm内放一个
struct ncclMemoryPool memPool_ncclRegMap; - 维护一个与原生对齐的队列,把这里的任务按顺序放上去。
if (comm->rank == sendRank && ipcRegistered[1] && ncclParamPassSm()) {
struct ncclRegAddrMap* mapping = ncclMemoryPoolAlloc<struct ncclRegAddrMap>(&comm->memPool_ncclRegMap, &comm->memPermanent);(&comm->memScoped);
mapping->sendAddr = sendAddr;
mapping->recvAddr = recvAddr;
mapping->sendBytes= sendBytes;
mapping->sendRank = sendRank;
mapping->recvRank = recvRank;
mapping->hasIpcMapping = true;
ncclIntruQueueEnqueue(&plan->mapAddrRegQueue, mapping);
}- 并在plan的reclamier清理资源的时候:
// Free register address mappings
struct ncclRegAddrMap* mp = ncclIntruQueueHead(&plan->mapAddrRegQueue);
while (mp != nullptr) {
struct ncclRegAddrMap* mp1 = mp->next;
// mapping is allocated from memScoped, will be cleaned up automatically
ncclMemoryPoolFree(&comm->memPool_ncclRegMap, mp);
mp = mp1;
}2.3 传输
launch阶段直接看当前mapping是不是有reg的任务,有的话直接cudaMemcpy到对端去:
// TODO: what if plan->kernelspecialized is true?
if (ncclParamPassSm() && plan->kernelFn == ncclDevKernelForFunc[ncclDevFuncId_P2p()]) {
struct ncclRegAddrMap* mapping = ncclIntruQueueHead(&plan->mapAddrRegQueue);
while (mapping != nullptr) {
if (mapping->hasIpcMapping && mapping->sendBytes > 0) {
CUDACHECKGOTO(cudaMemcpyAsync(mapping->recvAddr, mapping->sendAddr, mapping->sendBytes, cudaMemcpyDeviceToDevice, launchStream), ret, do_return);
CUDACHECKGOTO(cudaLaunchHostFunc(launchStream, hostProxySyncCallback, plan->syncCondition), ret, do_return);
INFO(NCCL_P2P, "Direct memcpy executed: %ld bytes from rank %d to rank %d", mapping->sendBytes, mapping->sendRank, mapping->recvRank);
}
mapping = mapping->next;
}
CUDACHECKGOTO(cudaLaunchHostFunc(launchStream, hostProxySyncCallback, plan->syncCondition), ret, do_return);
goto do_return;
}背景
引入registered buffer有两个初衷。其一,实现zero-copy,优化latency以及节省资源。其二,使用zero-copy避免了send/recv环节多次的send/recv操作,有可能解决无核训练hang问题。
Register buffer的升级主要体现在底层Net Transport和P2P Transport的实现中,现将这两部分的改动详述如下。
Net Transport
原生
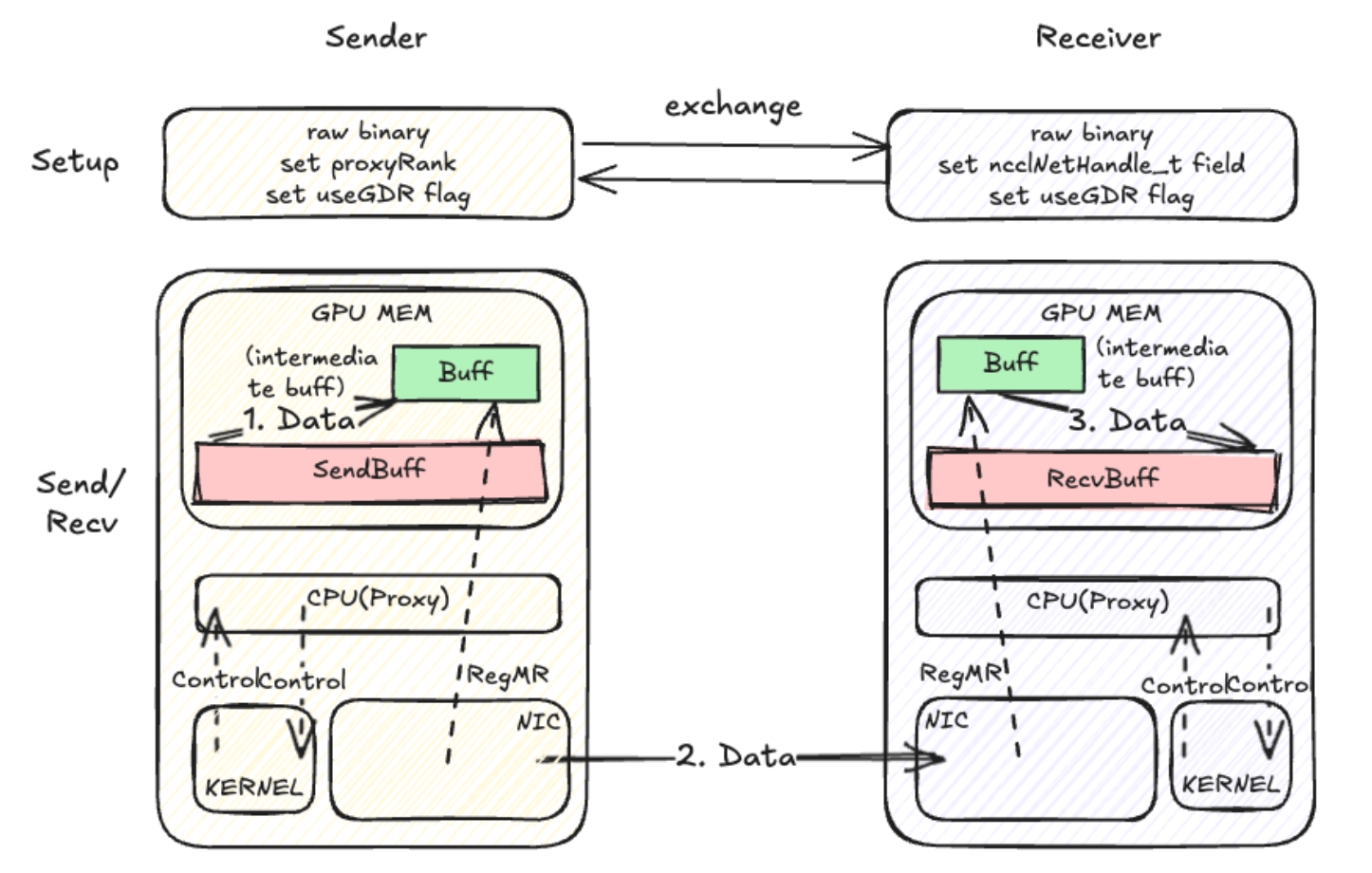 无核
无核
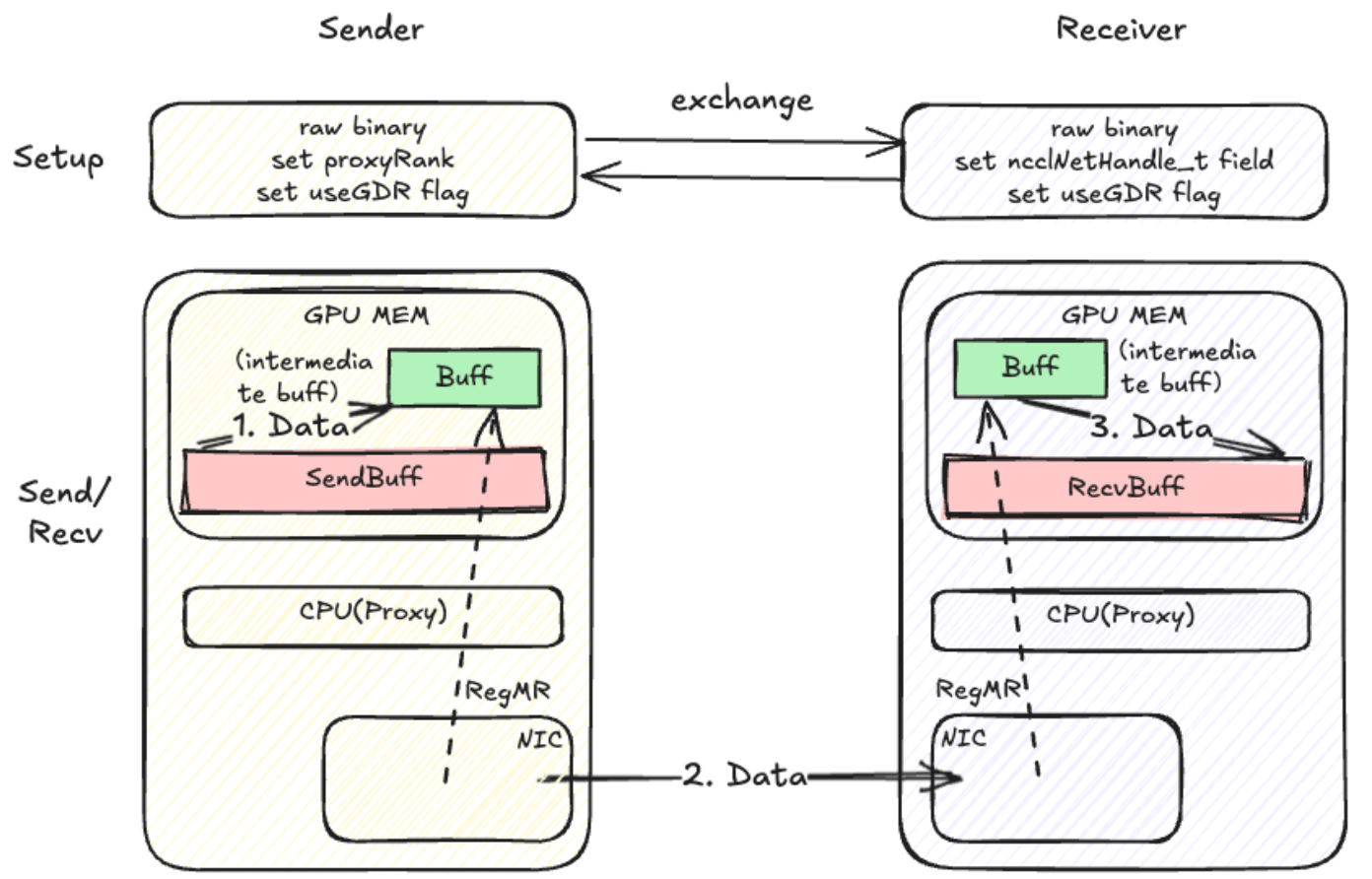 无核 with Register buffer
无核 with Register buffer
 Net Transport with PXN
原生
Net Transport with PXN
原生
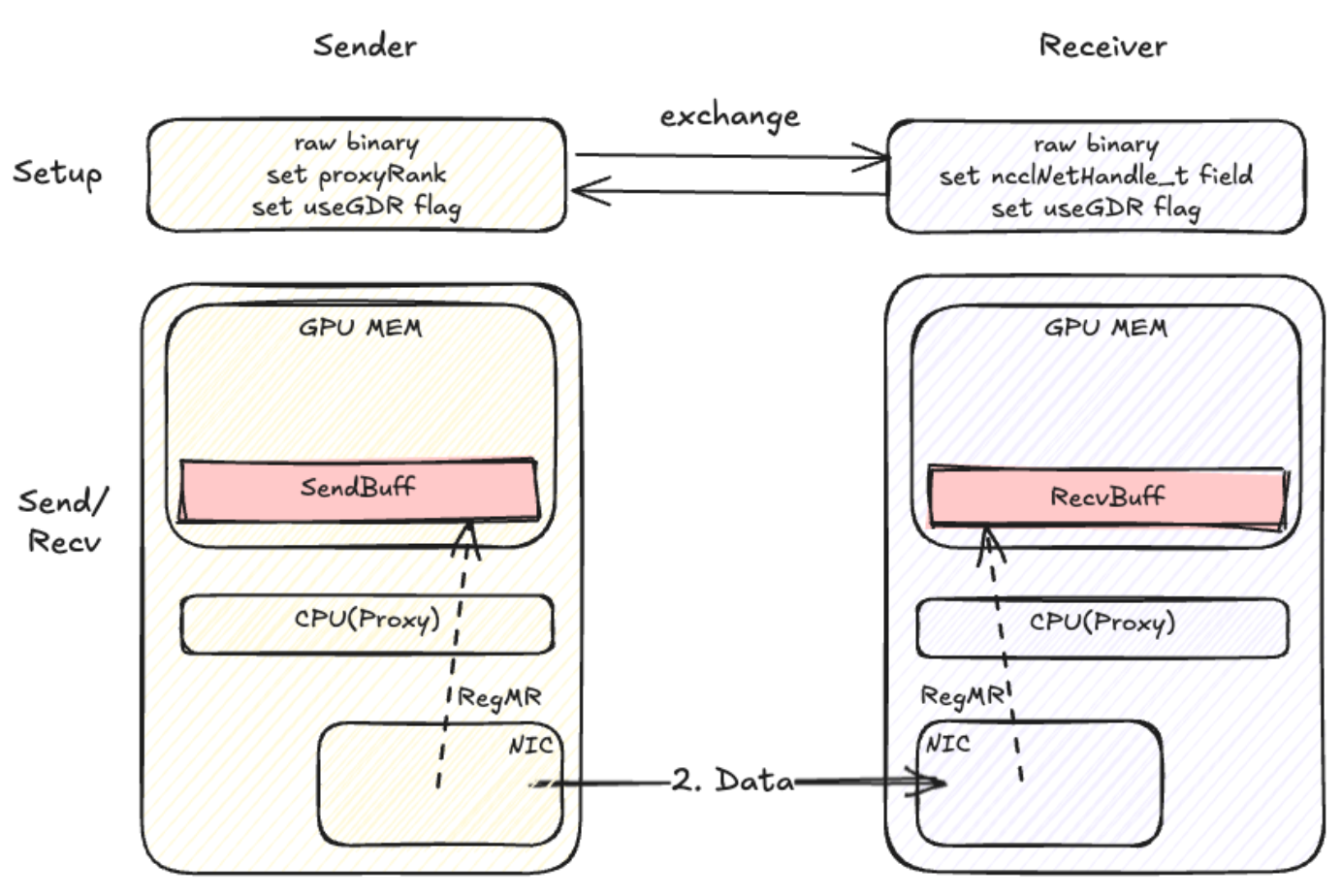
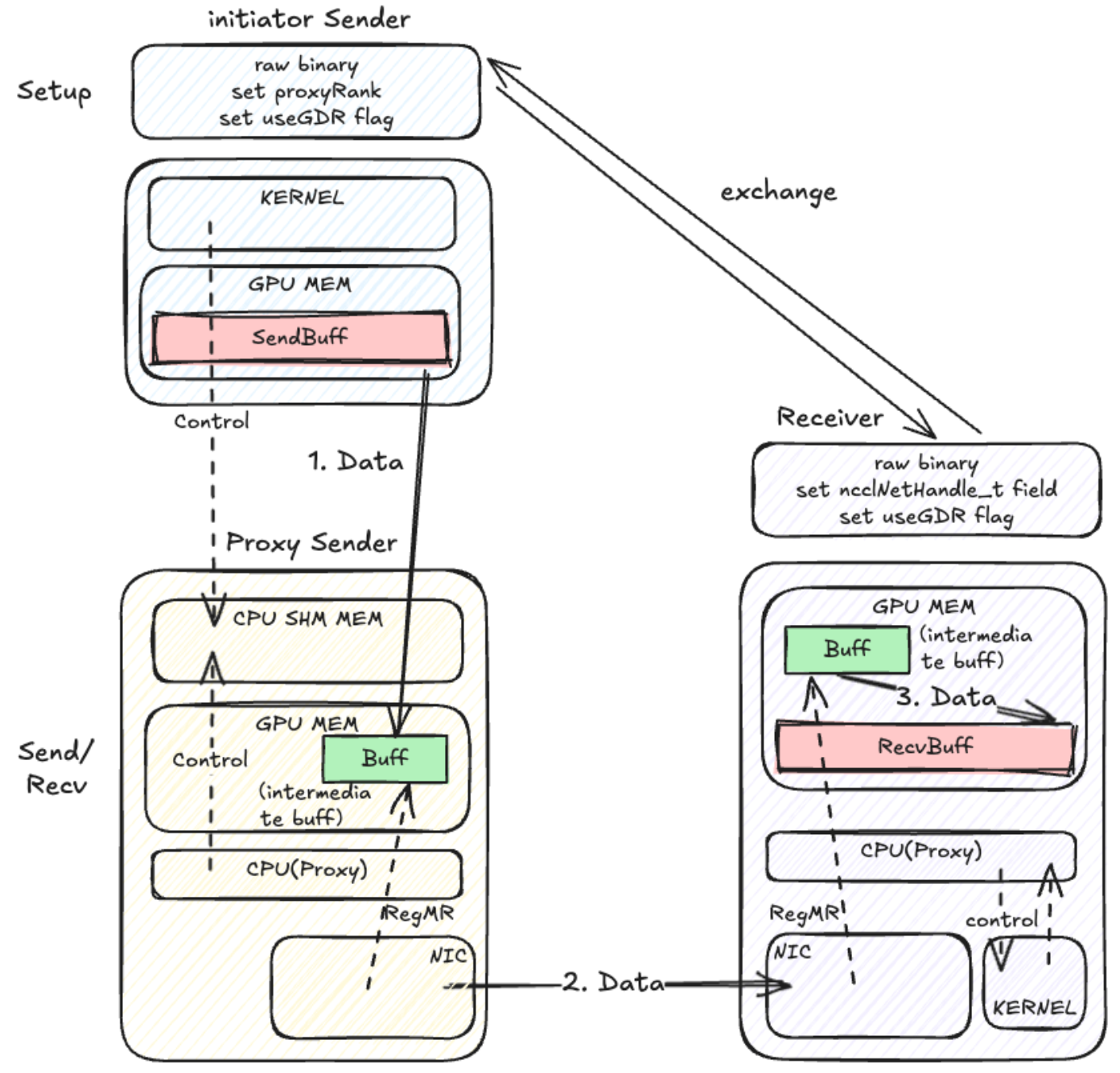 无核 with Register buff
无核 with Register buff
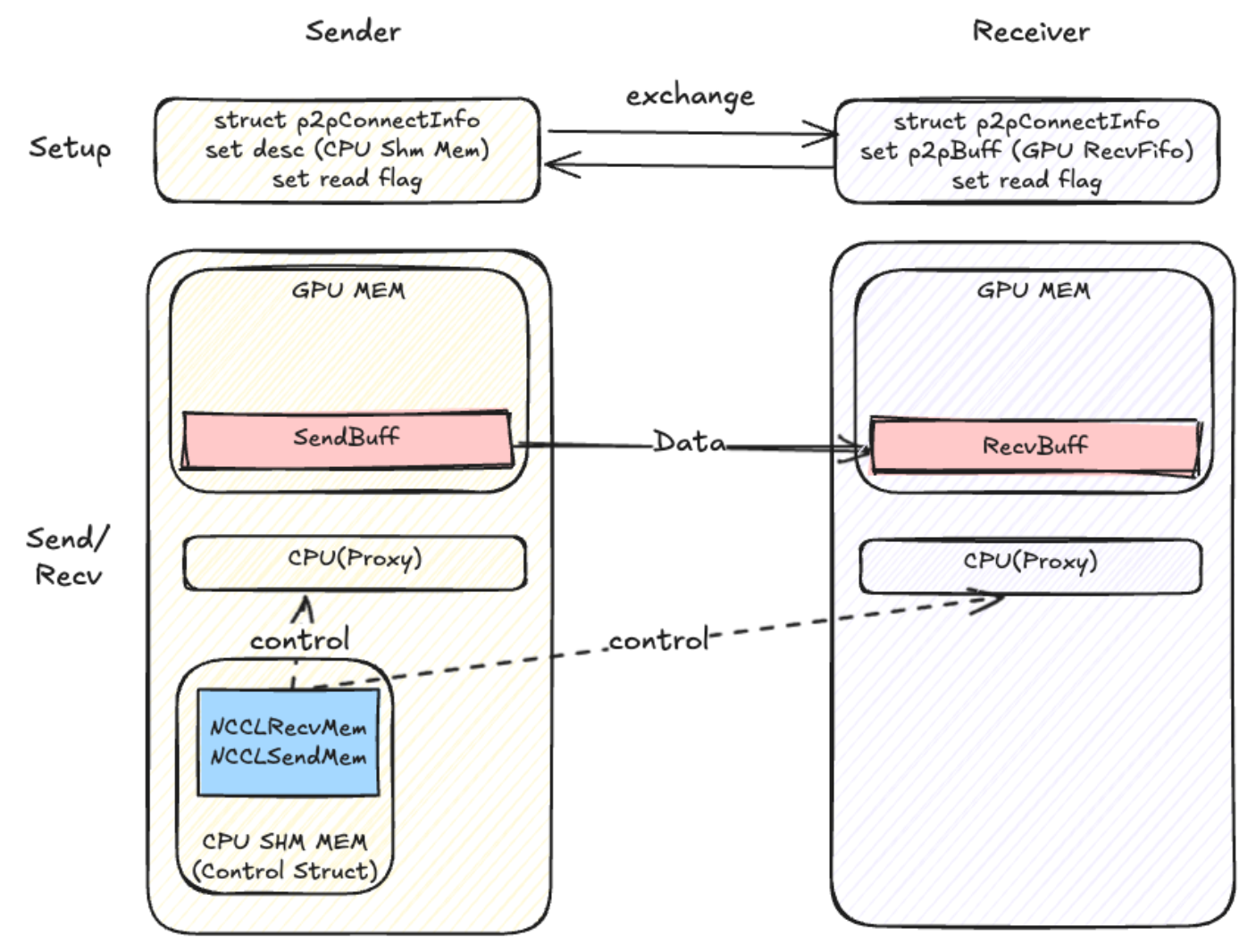
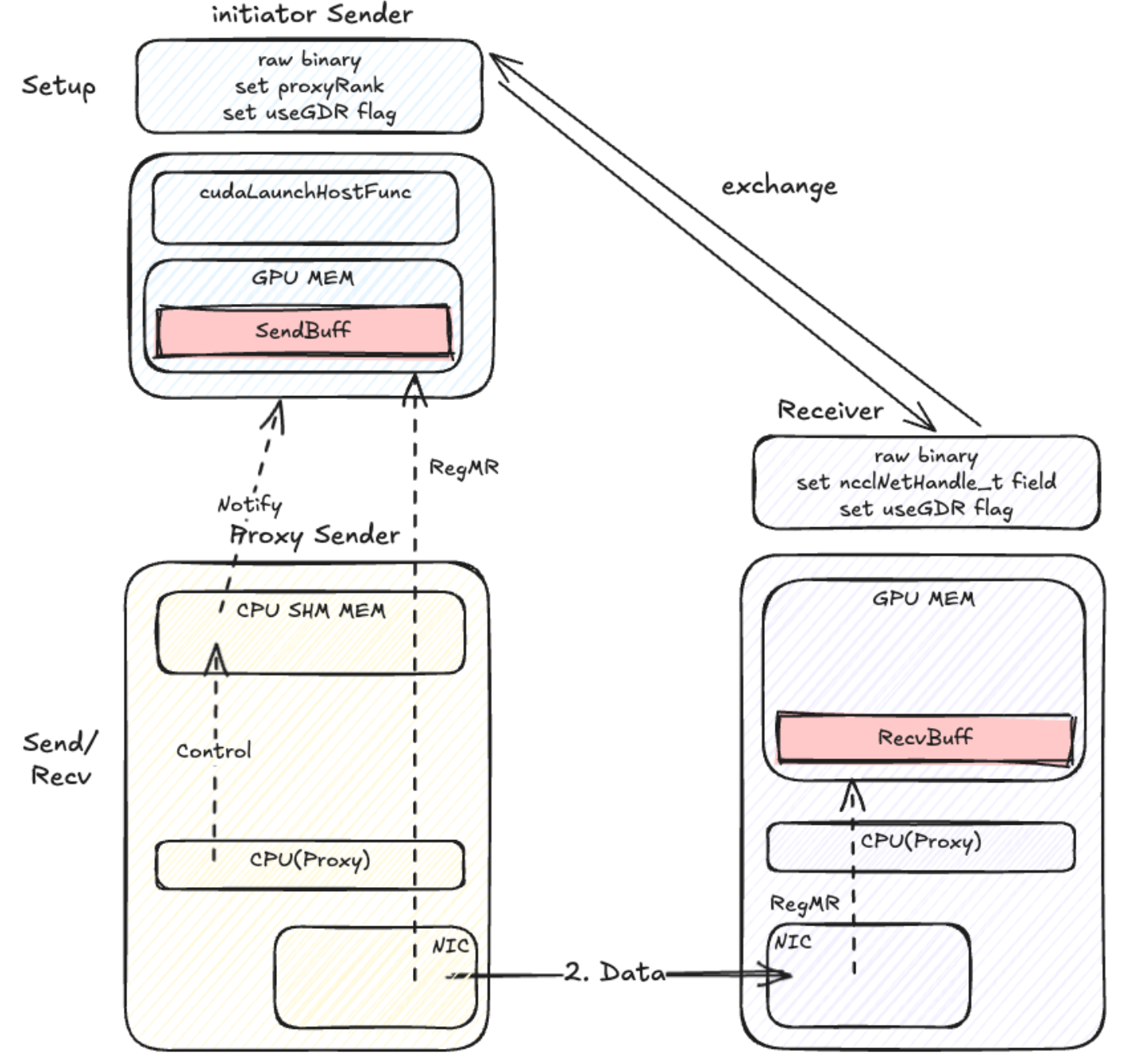 P2PTransport
无核
P2PTransport
无核
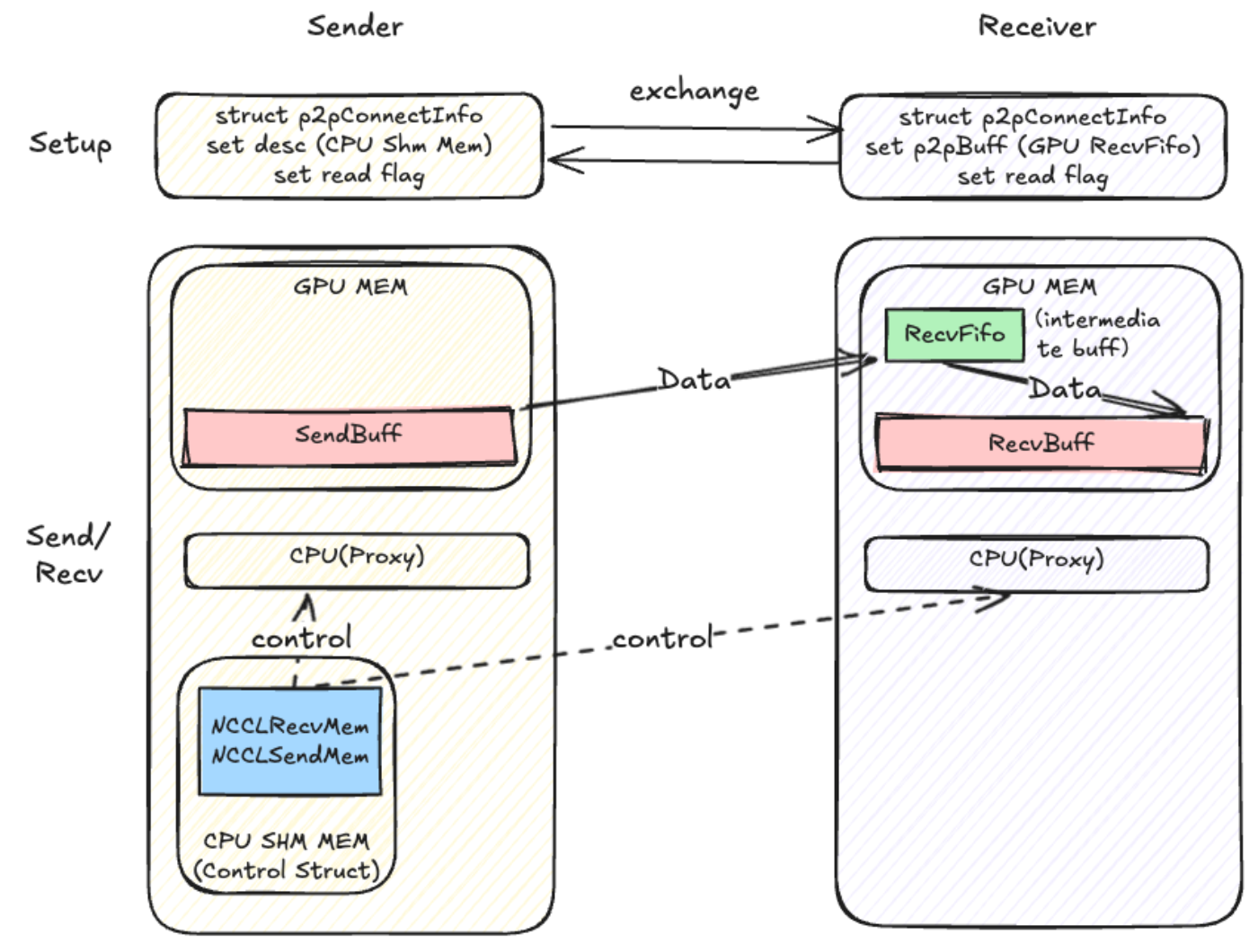
无核 with register buff