https://deepwiki.com/NVIDIA/nccl
1. 简要流程如下:
- 首先,每个要参与数据传输的GPU都要调用
**ncclCommInitRank**创建一个与其rank对应的Communicator,同一个communication group中的每个communicator具有相同的unique ID。 - 当每个设备调用
ncclCommInitRank时,设备之间会交换一些信息,例如各自的IP,bus ID等。然后检测整个系统中的网络拓扑结构。 - 有了网络拓扑结构,NCCL会进一步搜索当前网络中最佳的RING、TREE、CollNet图结构。
- 有了设备之间的图结构信息,就可以在存在通路的设备之间建立点对点的连接。主要有4种连接类型:p2p,nvls,network以及collnet。采用哪种方式取决于这两个节点之间支持怎样的连接方式。以上就是初始化阶段的所有准备工作。
- 初始化完成后,就可以调用集合通信原语。例如
ncclAllReduce。集合通信函数会被enqueue到一个CUDA stream上,在GPU上异步执行。 - 接下来在CPU上启动Proxy线程,作为GPU上集合通信kernel的代理,与GPU kernel协同完成与其他设备之间的数据传输。GPU kernel负责计算所需传输的数据的地址以及数据量大小,而Proxy线程负责完成实际的数据传输。对于采用p2pTransport 以及shmTransport的设备,在建立连接后可以直接传输数据,对于采用netTransport的设备,则需要通过socket进行数据传输。
以上a-d的过程大致如下图:
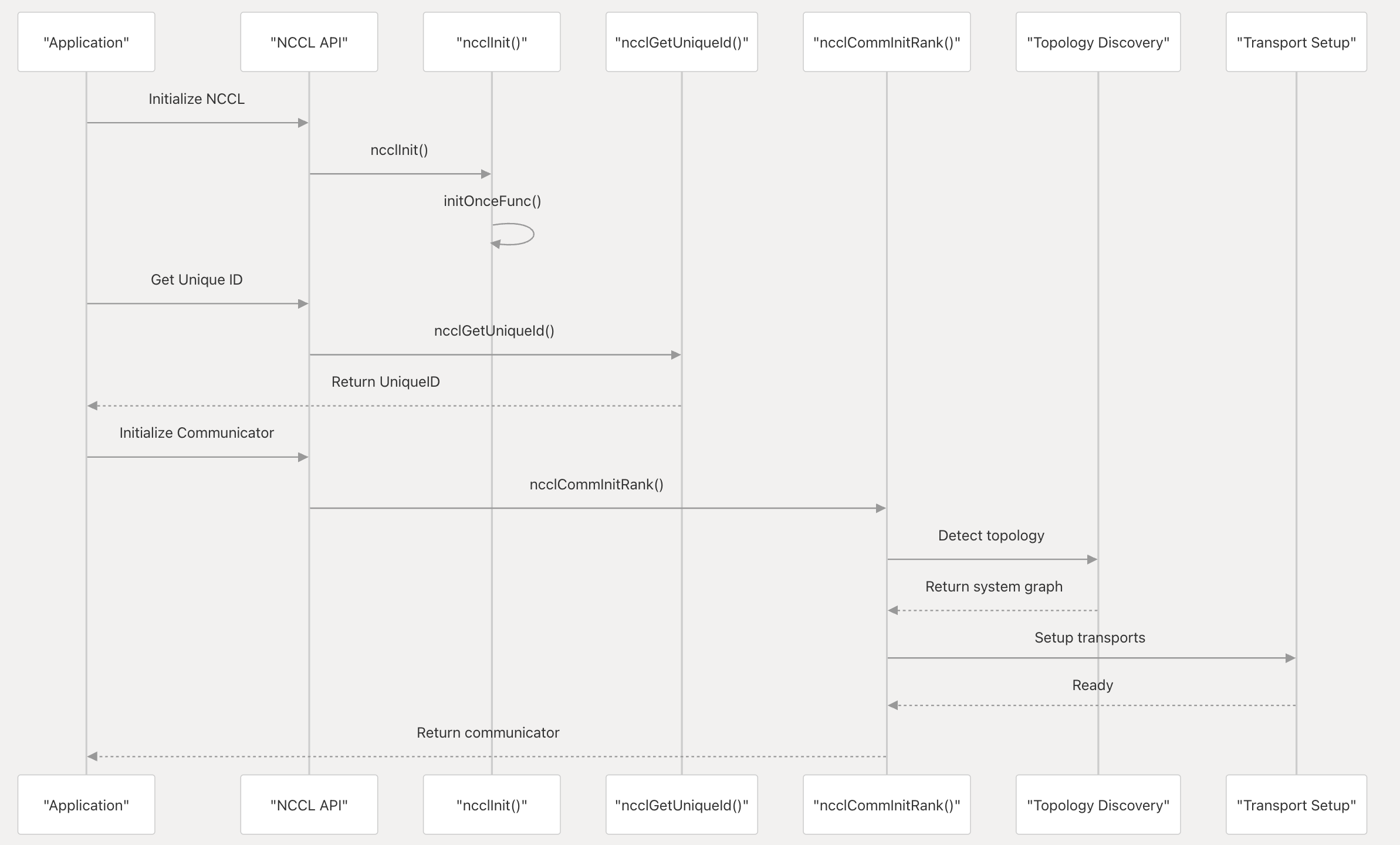
- 库初始化
**ncclInit()**:初始化全局状态 - 唯一 ID 生成
**ncclGetUniqueId()**:创建唯一标识符 - 通信器创建
**ncclCommInitRank()**:为特定等级初始化通信器 - 拓扑发现:分析系统硬件拓扑
- 传输设置:根据拓扑选择适当的传输
以上a-f的全过程的大致流程如下图:
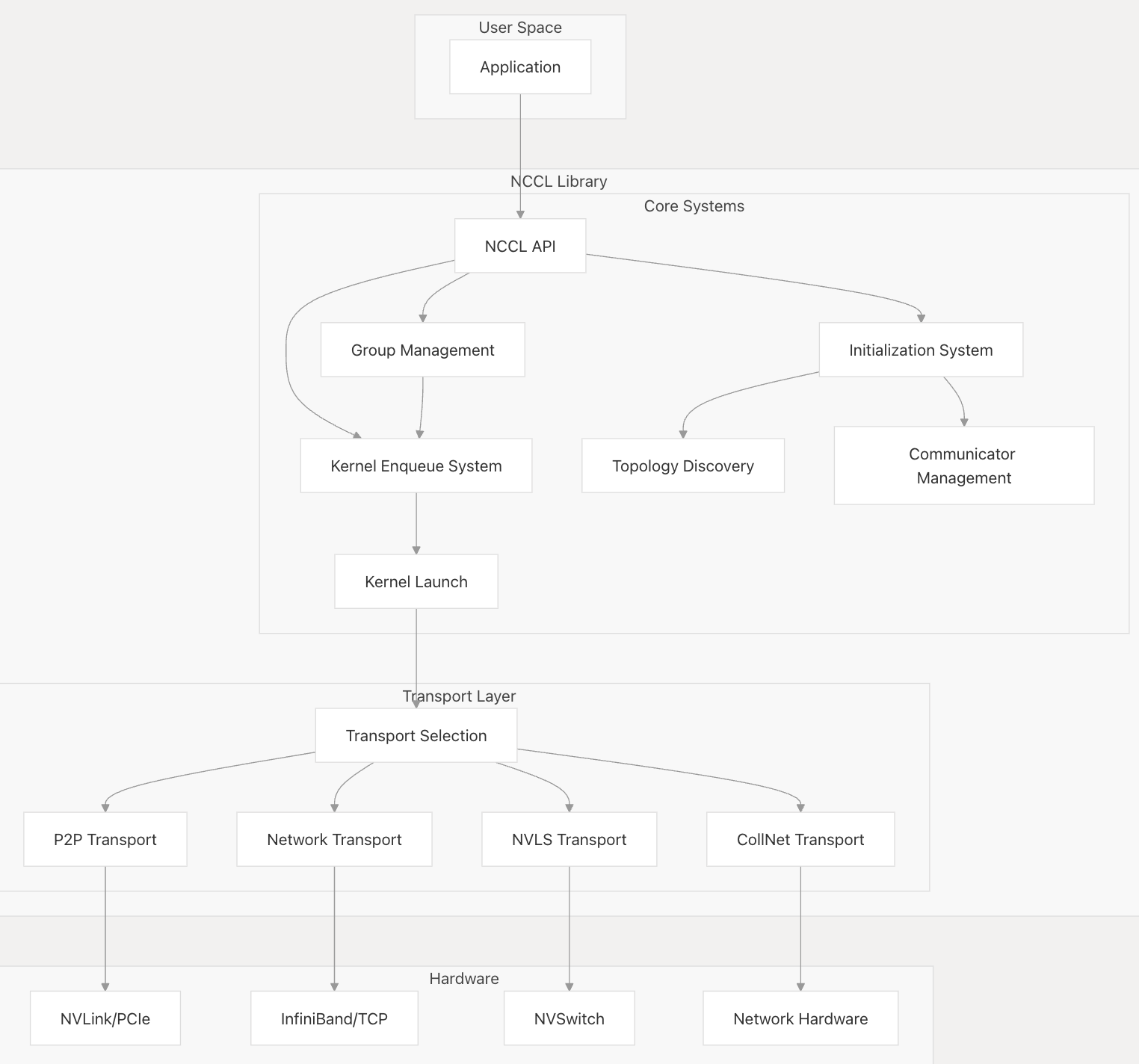
- API 层:为应用程序提供公共接口
- 初始化系统:处理库初始化和通信器设置
- 拓扑系统:发现并分析硬件拓扑
- 传输层:管理不同的通信方法
- 群组操作:协调跨多个设备的集体操作
- 内核启动系统:准备并执行 CUDA 内核
下面是详细的初始化→传输层(IB/RoCE,Socket,P2P,Proxy)→拓扑→集合操作→组→kernel启动
2. initialization system 初始化
init.cc内的ncclInit()会进行初始化
static ncclResult_t ncclInit() {
atomic load
mutex lock
initEnv();
initGdrCopy();
NCCLCHECK(bootstrapNetInit());
NCCLCHECK(ncclNetPluginInit());
initNvtxRegisteredEnums(); // 性能分析工具用的
atomic store
mutex unlock
}- 环境初始化 (initEnv()):设置nccl runtime环境变量 & 配置
- GDR 复制初始化 (initGdrCopy()):初始化GPU Direct RDMA(GDR)复制功能
- 引导网络初始化 (bootstrapNetInit()):inter-node(机间)的基础网络
- 网络插件初始化 (ncclNetPluginInit()):init第三方网络通信插件(
plugin.c示例文件中定义的功能)
这里1会去用userHomeDir()决定从用户主目录还是系统目录读取配置文件(环境变量),然后2会用wrap_gdr_runtime_get_version()和wrap_gdr_driver_get_version()当前gdr的runtime和driver的版本号。bootstrapNetInit这里同样用了mutex互斥锁保证bootstrapNet安全。
3. Topology System 拓扑
4. Group Operations
5. Kernel Launch System
6. Transport System
6.1 IB/RoCE传输
使用 IB 和 RoCE 网络,支持跨节点 GPU 之间的高性能通信,并利用远程直接内存访问 (RDMA) 功能实现低延迟、高带宽通信。
7. 通信操作
NCCL支持如下的集合通讯操作:
| Operation类型 | Description | Algorithms |
|---|---|---|
| AllReduce | Reduce data and distribute results to all ranks | Ring, Tree, CollNet, NVLS |
| Broadcast | Send data from one rank to all other ranks | Ring, Tree |
| Reduce | Combine data from all ranks to a single rank | Ring, Tree |
| AllGather | Gather data from all ranks to all ranks | Ring |
| ReduceScatter | Reduce data and scatter results to all ranks | Ring |
| Send/Recv | Point-to-point communication | P2P Transport |
- 算法(Ring、Tree、CollNet、NVLS)定义了“怎么通信”,即 策略与拓扑结构。
- Transport(p2p、nvls、network、collnet)定义了“通过什么通道通信”,即 底层的数据传输方式。
| Transport 类型 | 使用场景 | 通信路径 |
|---|---|---|
p2p | intra-node(单节点内) | GPU ↔ GPU(通过 NVLink/PCIe) |
network | inter-node(跨节点) | GPU ↔ NIC ↔ 网络 ↔ NIC ↔ GPU |
collnet | inter-node(有特殊网络拓扑时) | 类似 network,但有专用 topology/流程 |
nvls | 特定 intra-node(如 NVSwitch) | GPU ↔ NVSwitch ↔ GPU |
4. 重要结构体变量的关系图
ncclComm:
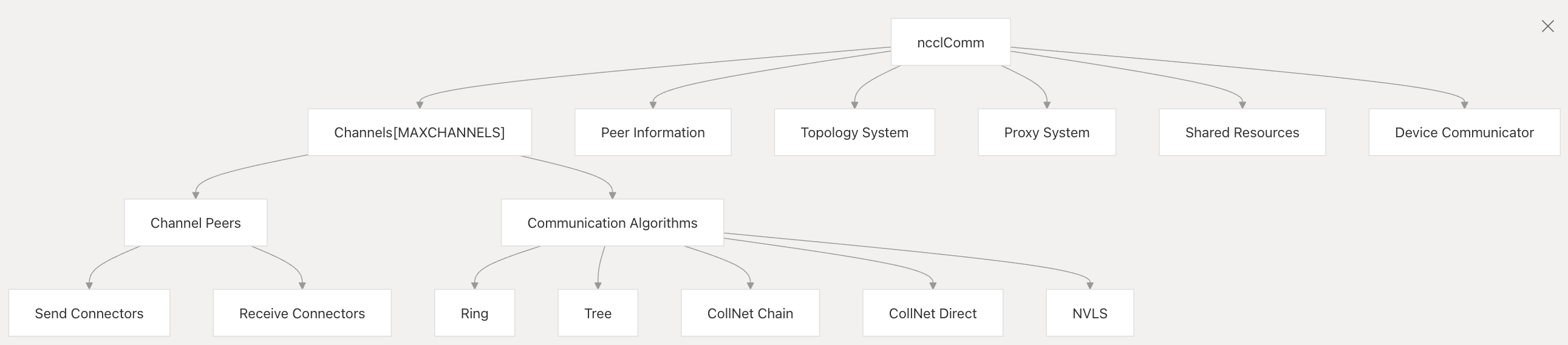
ncclTopoSystem:
