0. Introduction
由于现在支持了多channel的无核send recv,那么现在对于性能的影响主要就是四大项:
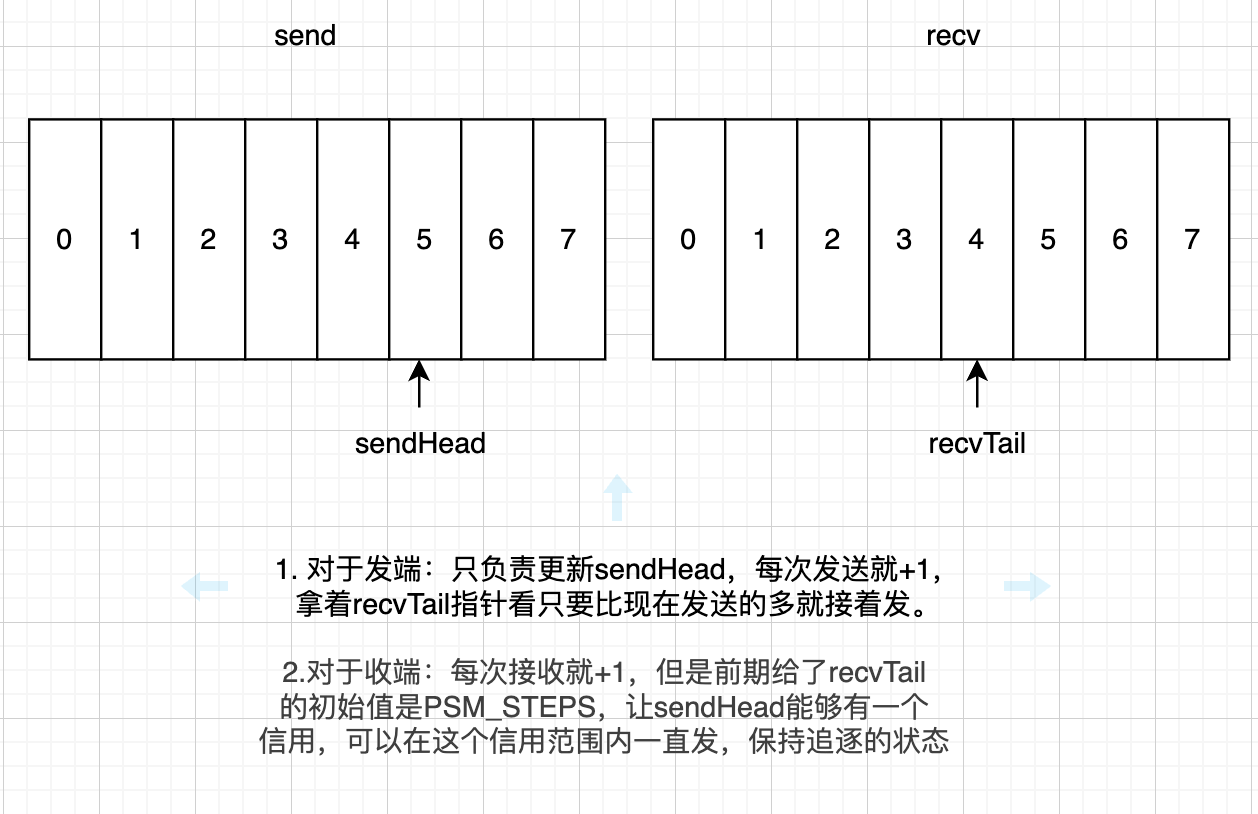
- buffersize 这是我们传输的时候用的recvFifo这快buffer(中转站)的大小,sender往上写,receiver从里面取,通过双指针控制双方的生产消费节奏。
- chunksize sender往buffer里面写一次数据的大小,receiver同理。通过公式(1)得到:chunksize = \frac{buffersize}{PSM\_STEPS}\tag{1}
- PSM_STEPS
这个参数就是说我这个中转站上有多少个槽,比如当前是8个槽。这里的每个槽就是一个chunksize的大小。
- nP2pChannels
这个就是nccl的环境变量
NCCL_MAX_P2P_NCHANNELS=x所等价的变量。默认是x = 32。底层send内的args会被这个nP2pChannels数整除,比如32MB数据,如果nP2pChannels=2,那么每个args就是16MB。这个切分是为了聚合相同opCount的操作,和我下面切分的槽不同。
1. baseline + compare
https://infrawaves.feishu.cn/wiki/VclxwuGHkiBWiKkdZZvcWM6Pnhf?from=from_copylink
经过测试发现,现在无核的NCCL_MAX_P2P_NCHANNELS环境变量对于cc是没有影响的。
公式(1)内的最多同时调整两个参数,也就是buffersize和psm_steps。并上现在的 NCCL_MAX_P2P_NCHANNELS 这个参数,现在优化无核p2p的参数集合就是:{buffersize, PSM_STEPS, NCCL_MAX_P2P_NCHANNELS }。
2. fine-tune the parameters
数据段包括三段:
- [1KB, 4MB)
- [4Mb, 256MB]
- (256MB, 8GB]
通过在不同大小数据段的n轮尝试后发现以下规律:
- chunksize 大于 64MB之后,基本上不再带来性能提升。chunksize小的时候对于小数据有性能提升。由于chunksize就是buffersize和PSM_STEPS的比,所以现在应该让chunksize随着数据的大小动态变化。
- 槽数大于2后开始性能变差。
- 机内无核在[1KB,256MB]的数据表现上超过原生,在512MB开始性能会差一些。
NCCL_MAX_P2P_NCHANNELS=2的性能最佳,如果等于1性能差,大于2不会带来提升。
所以优化思路总结为: 数据大,就加大buffersize降低槽数。数据小,就降低buffersize增加一个槽数。也就是说chunksize的取值是4MB和64MB之间,PSM_STEPS在1和2之间。NCCL_MAX_P2P_NCHANNELS固定为2。
3. modify code
src/graph/paths.cc在前期计算p2p topo的channel的API ncclTopoComputeP2pChannels 内我们修改comm→p2pnchannels在无核开启的时候是 std::min(comm->p2pnChannels, 2)。
修改后可以看到性能对齐在外侧环境变量的设置NCCL_MAX_P2P_NCHANNELS=2 :
然后就是transport的psm_p2p.cc内的progress内,需要对buffersize和PSM_STEPS动态调整。核心逻辑就是:
size_t dynamic_buffer = proxyState->buffSizes[p];
if (sub->nbytes >= PSM_BUFFER_SIZE) {
dynamic_buffer = PSM_BUFFER_SIZE;
} else {
size_t msize = sub->nbytes / (1024 * 1024);
int adjustFactor;
if (msize >= 32) adjustFactor = 1;
else if (msize >= 16) adjustFactor = 2;
else if (msize >= 8) adjustFactor = 4;
else if (msize >= 4) adjustFactor = 8;
else if (msize >= 2) adjustFactor = 16;
else if (msize >= 1) adjustFactor = 32;
else adjustFactor = 64;
dynamic_buffer = PSM_BUFFER_SIZE / adjustFactor;
}
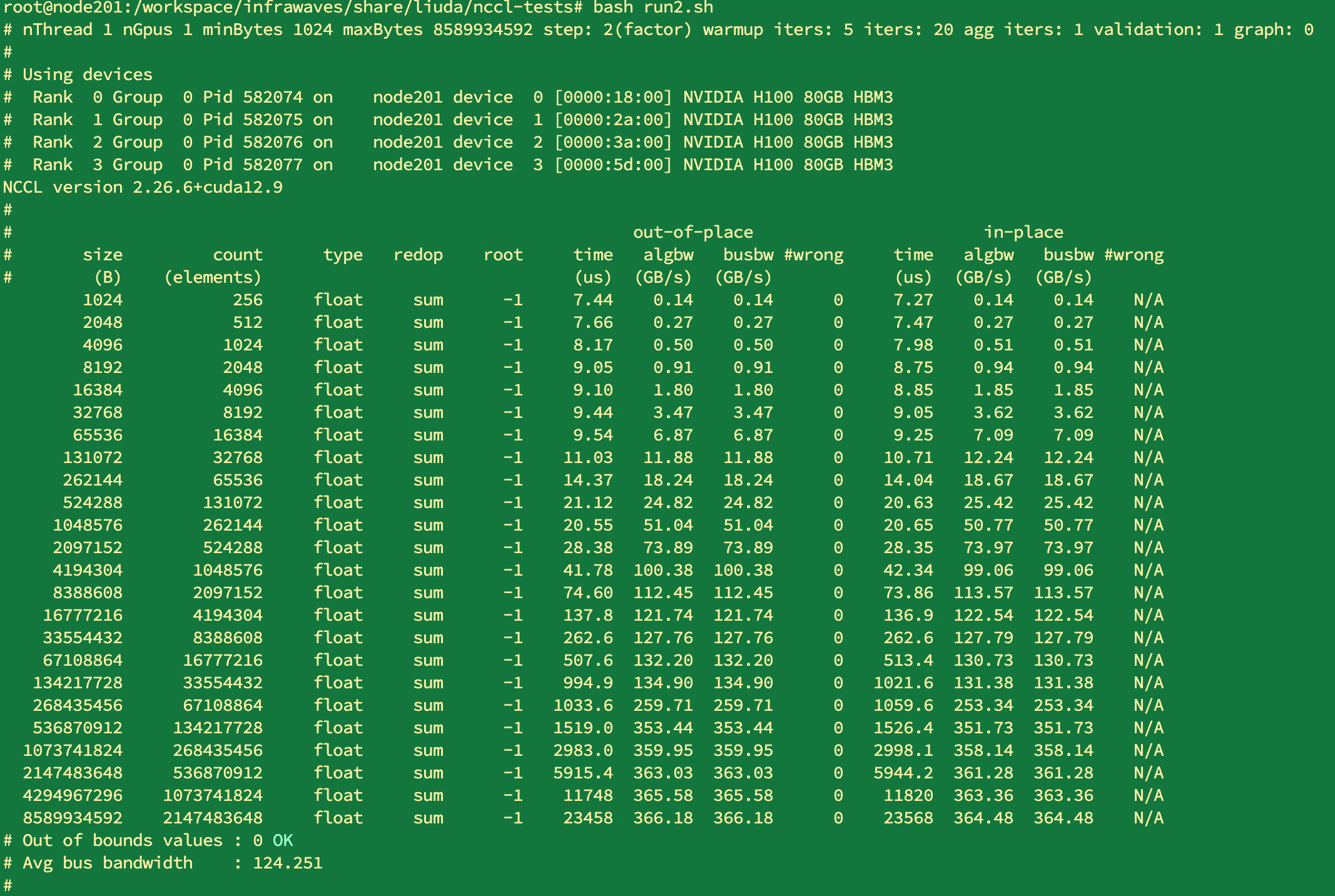
sub->chunkSize = dynamic_buffer / PSM_STEPS;让这里的chunksize与当前的数据的size贴近。 调整后1KB到8GB与原生的对比如下: 无核:
mpirun -np 4\
--host 10.1.3.201:4\
--allow-run-as-root \
-x NCCL_DEBUG=warn \
-x MASTER_PORT=29500 \
-x UCX_TLS=tcp,self \
-x LD_LIBRARY_PATH=/workspace/infrawaves/share/liuda/vc226/vccl_2.26.6-1/build/lib:$LD_LIBRARY_PATH \
-x NCCL_IB_GID_INDEX=3 \
-x NCCL_PASS_SM=1 \
./build/sendrecv_perf -b 1KB -e 8GB -f 2 -g 1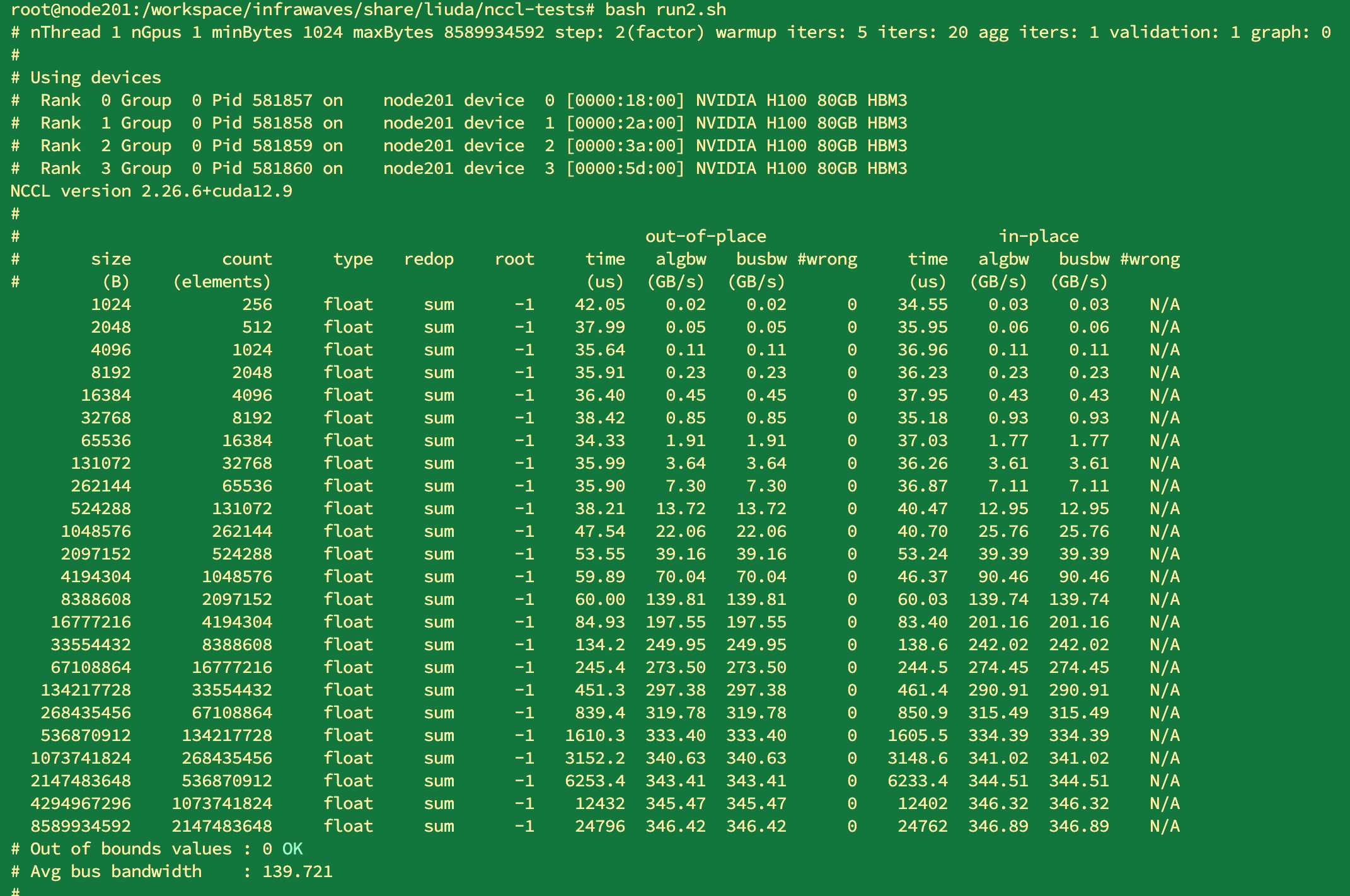 原生:
原生:
mpirun -np 4\
--host 10.1.3.201:4\
--allow-run-as-root \
-x NCCL_DEBUG=warn \
-x MASTER_PORT=29500 \
-x UCX_TLS=tcp,self \
-x LD_LIBRARY_PATH=/workspace/infrawaves/share/liuda/vc226/vccl_2.26.6-1/build/lib:$LD_LIBRARY_PATH \
-x NCCL_IB_GID_INDEX=3 \
./build/sendrecv_perf -b 1KB -e 8GB -f 2 -g 1