前言
关于TP = 1的bug
首先在早期我开 TP=1的时候在 moe 的 1F1B ep overlap 的时候,会出现某个 gemm 算子输入为 null 的情况,而 moe training 大部分为 tp1,所以在要想打开 --overlap-moe-expert-parallel-comm 则需要设置 "mlp": False,如下:
../Megatron-LM/megatron/core/models/gpt/fine_grained_callables.py
@internal_api
def should_free_input(name, is_moe, config):
// ...
free_input_nodes = {
"mlp": False,
"moe_combine": True,
"moe_dispatch": not (enable_deepep or enable_hybridep)
and (CudaGraphScope.moe_preprocess not in config.cuda_graph_scope),
}
// ...以上为我在2025.10.14在 Megatron-LM 提的 issue : https://github.com/issues/created?issue=NVIDIA%7CMegatron-LM%7C1862
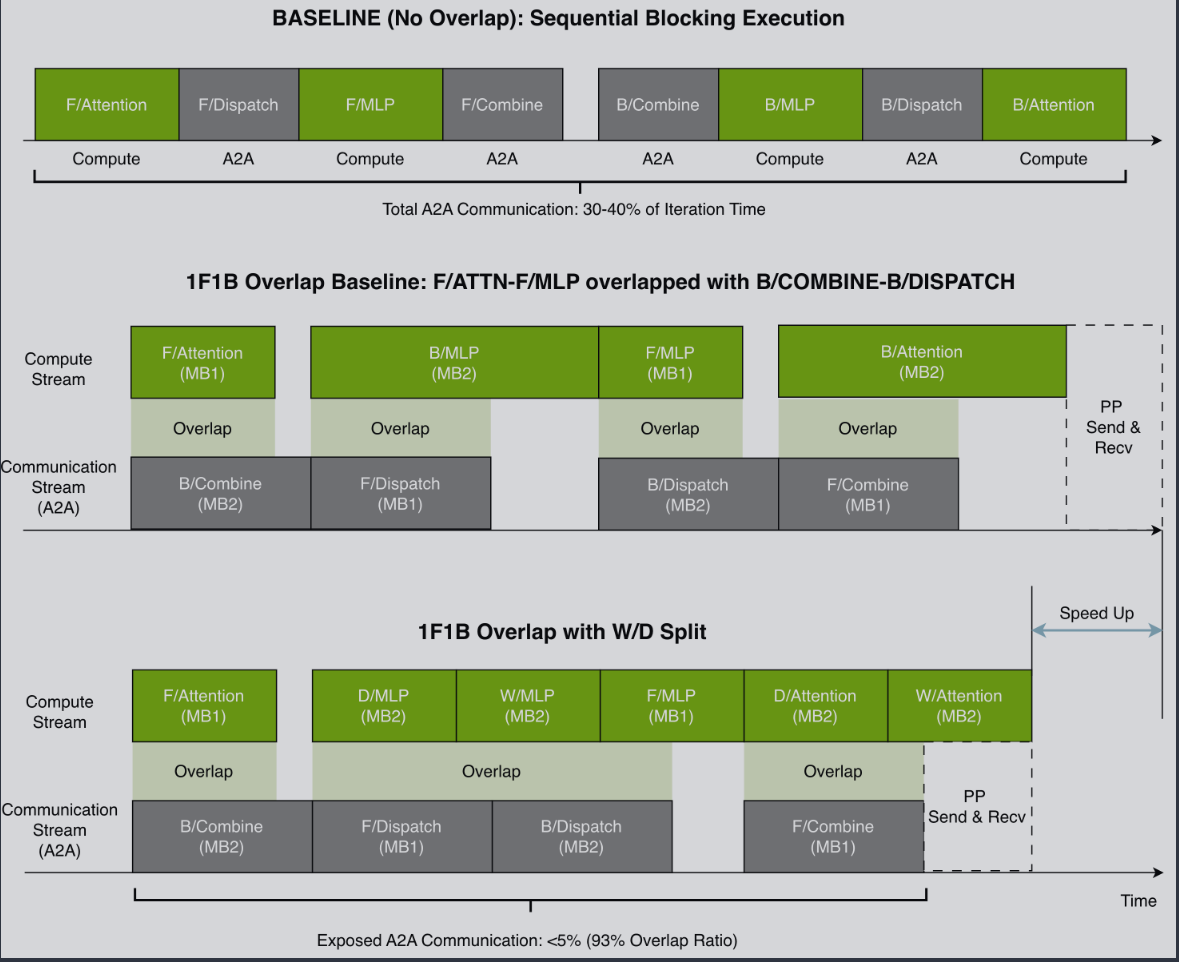
MoE 1F1B overlap
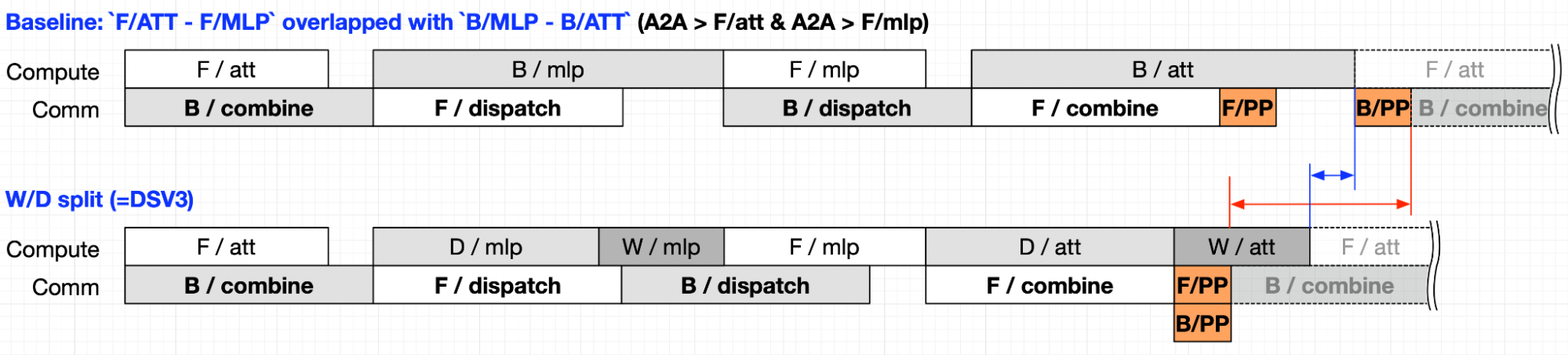
这里参考了 megatron 的论文内的图,核心就会原来不 overlap 的话 forward+backward 会和 a2a 纯串行,然后 baseline 内升级了两个 stream+两个 microbatch 的 overlap,这样就可以让通讯和计算 overlap。重点是 W/D 的进一步拆分后的 overlap:
- MB2 在 backward 的 mlp 阶段,权重和激活的计算拆开,激活的 Dgrad 先计算完,那么 MB2 的 Dispatch 就可以很快执行了,让其他 rank 也可以早早开始自己 layersN-1 的链式求导。
- MB2 的 attn 阶段同样把激活的计算拆开,一结束就可以让 pp backward的 send/recv提前并与 MB2 的权重的 attn 计算 overlap。 此时整个过程只剩下 2 个 babble;