vllm 版本:53b88d1dfc1f43cc9c7ead2c, 2026 年 6 月 2 日
0. vllm核心架构
vllm 构建了一套双进程多线程异步的在线推理框架,PD 分离场景 prefill 或者 decode 假设 tp8 dp1,这里会有 8 个 gpu workers,tp4 dp2的话这里任然是 8 个 gpu workers,但是会precess1 会变成 dp 个进程来分别处理各自的请求。
在 EngineCoreClient 的设计来看,设置了递归的 await 在两个异步 task 上,当 task2 收到 gpu 算完的输出会唤醒 task1 的处理,task1 完成输出的 token 拼装之后唤醒最上层 vllm serve 的请求结束。整个过程只有 1 个线程,无阻塞的进行。
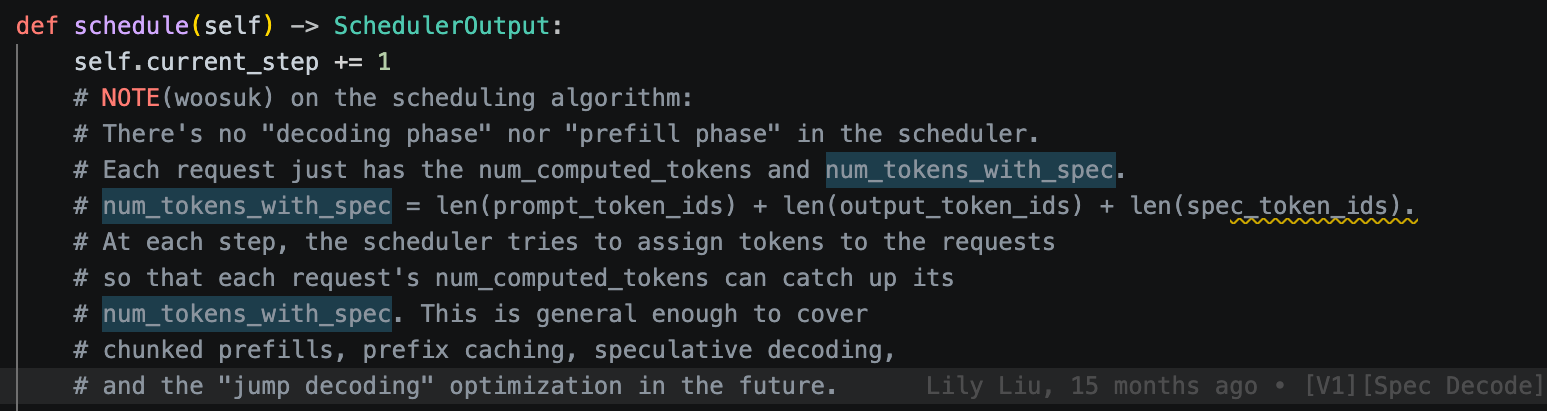
在 EngineCore 的设计来看,主要分为3 个线程+n 个 gpu worker 之间的协作,并且做到了 cpu 的计算和 gpu 的计算 pipeline。如下:
时刻 ──────────────────────────────────────────────────▶
main: [调度(占GIL)] [发kernel→放GIL........GPU 在算第N步........] [收结果]
input: [拿GIL反序列化][放GIL等下一条ZMQ...收到...][拿GIL反序列化]
output: [拿GIL序列化第N-1步结果][放GIL发ZMQ......发完]
注:GIL 为 global interpreter lock,即使多 python 线程也会被“串行+切换开销”,所以precess2内三个线程通过异步等 GPU 算完+异步 ZMQ + 两次 step 来做 cpu 线程间的并行。

1. scheduler && executor && kv cache && connector
假设模型为 30B moe,1P1D,80GB 显存,tp8。num_hidden_layers=48,num_key_value_heads=4,head_dim=128,8k 输入 1k 输出,325 条请求,rps=65,最大一个 batch 里面放 64k。
one token kv cache / per layer = 2(KV) x 1(KV head) x 128(head_dim) x 2(bf16) = 0.5KB one kv cache block = 8KB 9k 输入输出需要的 block 数量 = 24KB x 9216 / 384KB = 24576 个 block decode 的一个 gpu 有 54GB 给 kv cache(log日志看到的),那么最多就可以同时有 54 * 1024 * 1024 / 8 / 24576 = 288 个(8k)请求。理论值与实际打印值接近。
传统引擎把”处理 prompt(prefill)“和”逐字生成(decode)“当成两种不同的阶段分开调度,代码很割裂。V1 把它们统一成一件事:不管你是 prefill 还是 decode,都只是”进度条还差 N 个 token没算”。调度器只干一件事——给你分配这一步算几个 token。
- prefill 一个 1000 token 的 prompt = “进度条要前进 1000”(可以切块,一次前进一部分);
- decode 生成 1 个 token = “进度条要前进 1”;
- 投机解码一次验 5 个草稿 token = “进度条要前进 5”。
核心需要弄明白俩个事情,一堆请求进来的时候:
-
vllm schedule 不严格的 FCFS(first come,first served) 是怎么做的? 假设 325 条 8k 输入进来,都是均匀的就会默认就是严格的 FCFS,不均的 32k+1K+8K 输入的时如果长的请求 kv 拉的慢没收完,就会被丢到 skip waiting,当前 step 就会先去看下一个请求。
-
P 和 D 怎么控制当前流速和 overlap 的?
流速: 325 条 8K 输入,每秒 65 条8k进 prefill,即一个 batch 有 8 条 req。进来超过 256 条在飞的请求之后,kv cache 满,就无法继续给你分配 kv cache block,故会通过抢占策略+缓存命中的方式去处理这种 case。
overlap:
这里从kv cache 角度分析 decode 侧计算与 pd 传输的 stream 上 overlap 来看,结论为:
- 如果 kv cache 不够大,那么很容易被 prefill 以一个很慢的带宽打满,那么 decode 侧每次的 forward 和 空出来新的 block给 prefill 传kv cache 进来 就会完全串行。
- 如果 kv cache 够大,那么每次 prefill 传进来的正好 decode 侧吃满计算的请求 cache 进来之后,每次 decode forward 计算和prefill 传 kv cache 进来就可以完全 overlap,完全并行。
下图为调度+执行+kv cache 分配管理+抢占 kv cache block+缓存命中的流程示意图,不同角色对应上图中 main thread 和 gpu worker 的工作。

2. 问题
- D 的能力在各种 workload 下不同,达到最大能力后,此时瓶颈为 kv cache 大小,如果 kv cache 无限大,那么瓶颈又在于最大能力,两者之间的平衡点(即 pd 配比,单测 D 的能力和 P 的能力 算出配比的话 假设 1P 能力完美打满 3 个 D 的消费)
- 不同 size 的传输下,多 thread 下 wr 已经完全打满 RNIC 的 QP 流水,大小不一不连续的 10GB 的一堆 kv cache block 在某 engine 的 one side rdma 传输接口上理论和实际值(Bwt)是多少?
- Bwt 如果已知是波动的,decode 的消费速度和 prefill 的产生速度能测出曲线,kv cache也已知,如何配比如何切分策略?
- KV 大小是否已经接近网络/PCIe/RDMA瓶颈;
- P 侧 batch 是否被 KV transfer 阻塞;
- D 侧是否等 KV,还是 decode 本身已经瓶颈;
- prefix cache hit 是不是值得搬;
- 多轮请求是否应该 append-prefill locally;
- P/D 比例是否匹配 input/output 分布。
3. related work
| 来源 | 备注 | addr |
|---|---|---|
| vllm report | https://vllm.ai/blog/2026-05-06-mooncake-store?utm_source=chatgpt.com | |
| UChicago | 1. 假如能让 kv cache block merge 成 1MB,那么就可以立刻拿到 80% 网络带宽 2. | http://arxiv.org/abs/2510.09665 |