0. introduction
在 vllm 传输 kv cache 的过程中,主要包括 mooncake,nixl,nccl…。其中 nccl connector 的实现过于丑陋,实际推理服务无法稳定/高性能使用。原因参考:0. vllm 如何使用 nccl 传输 kv cache 1. Bugfix for vllm deepseek v3.2 1p1d 2. vllm use vllm-plugin-fl、flagGemms and flagcx run Deepseek v3.2。
原本的双边需要 receiver 提前 empty 一块内存来让 sender 有 dst_addr,在高并发/系统过载的推理服务场景,这会进一步和 kv cache 抢占 VRAM/DRAM。因此需要一个类似 mooncake/nixl transfer engine 的单边调用 ibv_post_send 来完成 kv cache 传输,即:nccl/flagcx 内就是 putSignal 的实现。
1. design
主要分为 3 部分:
- 在 tp group 内给所有 P 到 D 的 rank来创建 FlagcxHeteroComm,在增加 P/D 的动态扩缩容的情况下就不用全局所有节点重启。
- 给 request 重排成 task/ 切slice,类似 mooncake。
- 在 pair 内用 flagcxOneSideRegister 完成基础的 rkey,MR,gid 的注册,在实际传输的时候由 receiver 去用写 ZMQ 告诉 sender 们我需要哪些 kvcache block(顺便把 dst_addr+rkey+gid带上),在 sender 们拿到后直接下单边的 putSignal,receiver 根据需要接收的 slice 数量去 waitValue。
1.1 已知问题
a. 解决不同comm无法注册的问题
首先当前的注册存在一个问题就是:prefill 的 rank0 会跟 comm1 的 rank0 注册,也跟 comm2 的 rank1 注册。然后因为 flagcx 内注册发现是自己(comm→rank)直接返回了就不注册了,rank0 的注册完的 key/Mr/gid 啥的就都不能给 deocde 的 rank1 用。
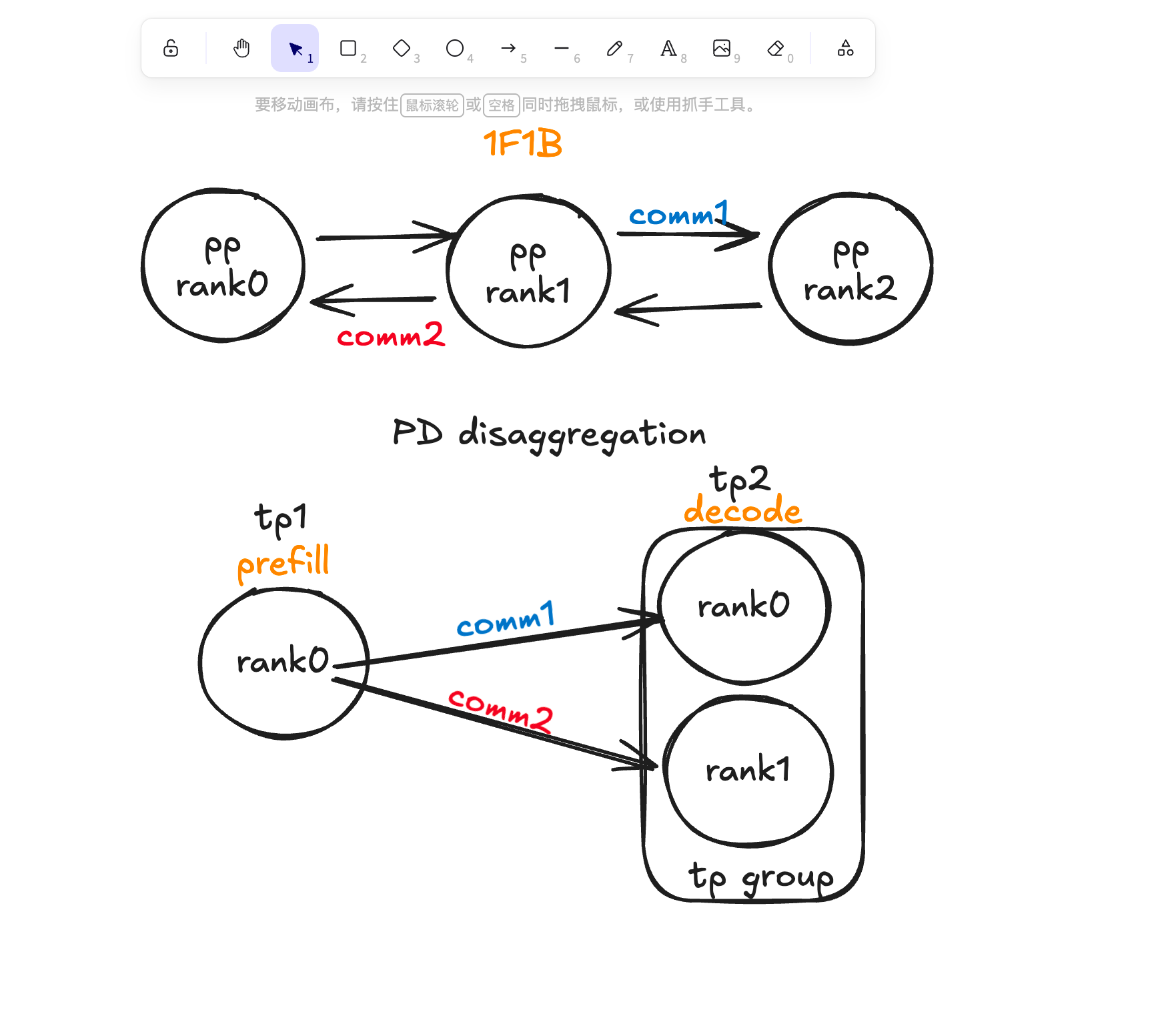 于是,在 flagcx 内增加 pr 修复,来支持 asymmetric 的 PD disaggregation TP 配置。0. flagcxOneSideRegister 支持 comm 隔离。
于是,在 flagcx 内增加 pr 修复,来支持 asymmetric 的 PD disaggregation TP 配置。0. flagcxOneSideRegister 支持 comm 隔离。
b. initRank + OneSideRegister
给不同 tp/pp/ep下的 kv cache的 sender/receiver 建立 comm 以便后续能够注册, 只开 tp 为 common case,这里不讨论,ep 也不会影响 attention 计算后的 kv。目前已知的问题主要是开 pp 时mooncake/nixl存在端口冲突问题。
mooncake 开 PP2 TP2 DP2 则会出现以下情况:

简单来说,mooncake connector 的每个 gpu 使用 ip:port 是通过 base_port(这里假设 9998)+ tp rank 得到。当开了 pp 之后,这里存在不同 pp stage 的 tp0 使用相同的 port。
nixl 开 pp2 tp2 dp2 的时候情况如下: nixl 的 zmq 监听端口计算方式:listen_port = base + vllm_config.parallel_config.data_parallel_rank
| Worker | tp_rank值 | KV cache 内容 |
|---|---|---|
| PP stage 0, TP rank 0 | 0 | 第 0~N/2 层 |
| PP stage 0, TP rank 1 | 1 | 第 0~N/2 层 |
| PP stage 1, TP rank 0 | 0 (冲突!) | 第 N/2~N 层 |
| PP stage 1, TP rank 1 | 1 (冲突!) | 第 N/2~N 层 |
- tp_rank 在不同 PP stage 之间是重复的(都是 0 和 1),最终
vllm/v1/engine/core.py的content.update()让后一个 PP stage 的 metadata 把前一个覆盖掉。
nixl:https://github.com/vllm-project/vllm/issues/30501 mooncake:https://github.com/vllm-project/vllm-ascend/issues/4244
comm 创建核心待解决问题就是:
当出现 PP 切分了 layer 之后,不同 pp stage 内相同 tp_rank index 需要有隔离的能够传递 metadata 的通道来通知 sender/receiver各自下一个
flagcxCommInitRank。
1.2 最终方案
综上,我们的 initRank 和注册逻辑设计为:
Decode 侧 Prefill 侧
────────────────────────────────────────────────── ──────────────────────────────────────────────
[启动阶段] register_kv_caches()
_decode_listener_thread 起来 _sender_thread 起来
ROUTER bind: host:port+tp_rank ROUTER(frontend) bind: host:port+tp_rank
等待 "NEW" 握手 PULL (backend inproc) 等 worker 回执
_sender_executor 线程池就绪
[请求到达] start_load_kv(metadata)
按 (remote_host, remote_port+tp_rank) 分组
每个 path 起一个 _receive_kv 协程
挂 PendingSignalWait 到 _active_signal_waits
_receive_kv(path, req_blocks, pending_wait):
1. 构造 FlagCXAgentMetadata
(req_ids, block_ids, base_addr, hostname, port)
2. 创建 REQ socket (connect → path)
setsockopt RCVTIMEO = 120s
3. await sock.send(encoded_data) ───────→ frontend(ROUTER) recv_multipart
├─ identity, _, metadata_bytes
└─ _sender_executor.submit(_sender_worker)
_sender_worker(identity, metadata_bytes, backend_path)
├─ decode metadata
├─ decode_listener_addr = host:port+tp_rank
├─ 若 pair_comms[decode_listener_addr] 不存在:
│ _create_pair_comm(decode_listener_addr) ← Prefill 主动发起
│ ├─ uid = flagcxGetUniqueId()
│ ├─ DEALER connect → Decode ROUTER
│ ├─ send({cmd:"NEW", uid:uid_bytes}) ──┐
│ ├─ flagcxCommInitRank(2, uid, rank=0) ←┐ │
│ ├─ _register_kv_for_comm(comm) │ │
│ │ ├─ flagcxOneSideRegister KV MRs │ │
│ │ └─ flagcxOneSideSignalRegister │ │
│ ├─ sock.recv() ← 等 Decode "OK" │ │
│ └─ pair_comms[addr]=PairCommInfo │ │
│ (comm, my_rank=0, signal_buf, │ │
│ signal_counter=0, send_lock) │ │
│ │ │
_decode_listener_thread: ←─────┼──────────────────────────────────────────┼──┘
recv (identity, "NEW", uid) ────┤
├─ flagcxCommInitRank(2, uid,rank=1) ← rendezvous ─────────────────────────┘
├─ _register_kv_for_comm(comm)
│ ├─ flagcxOneSideRegister KV MRs
│ └─ flagcxOneSideSignalRegister
├─ pair_comms[remote_addr]=PairCommInfo(comm, my_rank=1,...)
└─ router.send_multipart([identity, "OK"]) ── 回给 Prefill DEALER
├─ expected_signal = _send_kv_to_decode(meta)
│ ├─ 轮询 reqs_need_send 最多 30s
│ │ 等 start_load_kv 把 local_block_ids 填好
│ │ + send_meta.ready.set()
│ └─ _send_blocks(send_reqs, meta)
│ ├─ 摊平为 xfer_list
│ │ (per layer × per contiguous group × per req)
│ ├─ with pair_info.send_lock:
│ │ pair_info.signal_counter += 1
│ │ expected_signal = signal_counter
│ │ for i, xfer in enumerate(xfer_list):
│ │ sig_val = 1 if i==last else 0
│ │ flagcxPutSignal(..., sig_val)
│ │ └─ 远端 signal_buffer 原子 +sig_val
│ └─ return expected_signal
├─ finished_sending_reqs += req_ids
└─ reply = str(expected_signal).encode()
│
▼
PUSH(inproc) → backend(PULL)
frontend.send_multipart([identity, "", reply])
│
4. reply = await sock.recv() ←──────────────────┘
(payload = b"123" 这样的整数;出错回 b"ERR")
5. expected_signal = int(reply)
6. pair_info = pair_comms 里唯一那条(由 listener 握手阶段建好)
pending_wait.comm = pair_info.comm
pending_wait.peer_rank = 1 - pair_info.my_rank
pending_wait.signal_value = expected_signal
7. pending_wait.ready.set()
8. finished_recving_reqs.update(req_ids)
[forward 推进] wait_for_layer_load()
waits = _active_signal_waits.pop_all()
for w in waits: w.ready.wait(60) ← 等所有 ZMQ REP 都回来
valid = [w for w in waits if w.comm and w.signal_value>0]
max_wait = max(valid, key=signal_value) ← counter 单调,等最大值即覆盖其余
flagcx_stream = adaptor_stream_copy(current_stream())
flagcxWaitSignal(max_wait.comm, max_wait.peer_rank,
sigOff=0, max_wait.signal_value, flagcx_stream)
└─ GPU 侧 poll signal_buffer ≥ expected,RDMA 落地后继续 forward
2 bugfix
- debug flagcx connector ✅ 2026-04-16
-
【bug1】看到flagcxWaitSignal 报错raise RuntimeError(f”FLAGCX error: {error_str}”)
- 确定了 error 码是 1,就是Unhandled device error ⬇️
- 先增加了 comm 初始化 并发的隔离,未解决,但是代码保留 ⬇️
- 然后怀疑是 context 用了其他的 cudaDevice 导致的,加了setCurrentDeive之后导致会出现 hang,不会直接报错。问题不在这,因为打印发现 worker 线程都是这样用的,并且和 mooncake 使用的方式是对齐的,问题不在这。❌
- sanitizer 排查内存问题,
- sanitizer 跨机给出的 error 分别有:
cudaErrorNoKernelImageForDevice(error 209) on cudaGetLastError,CUDA_ERROR_NOT_PERMITTED(error 800) on cuMemCreate,CUDA_ERROR_NOT_SUPPORTED(error 801) on cuMemGetHandleForAddressRange. 三类错误分别是没指定sm90,VMM 不知道为什么分配被拒,不支持ncclCommWindowRegister。❌ - 发现flagcxOneSideBuildFullMesh内存在下面问题,需要结合 flagcx.cc内flagcxOneSideBuildFullMesh的 for 循环来看:
问题是,这里在和 mc 讨论中发现 mpich 启动的测试从来不会出现问题,我用 openmpi 会出现问题。就算这里加上 barrier,在 pd 分离的时候依旧会出现 decode 出一样的报错。❌时间轴 ──────────────────────────────────────────────────────► rank0: [i=0: self↔self] ──完成──► [i=1: while循环开始] └─ connect(rank1.listen) TCP 进入 rank1 的 accept queue accept(rank0.listen) 等待 rank1 来连 rank1: [i=0: while循环] connect(rank1.self) TCP 进入 rank1 自己的 accept queue accept(rank1.listen) ← rank1的accept queue里现在有2个连接: [A] rank1 自己(self-connect, i=0预期) [B] rank0 发来的 (i=1来的, 不该这轮消费) OS 的 accept queue 是 FIFO,但 [A] 和 [B] 谁先到是竞态。如果 rank0 的 TCP connect 先到: rank1 的 accept() 拿到了 [B] (rank0 的 i=1 连接) → recvComm 设置为来自 rank0 的连接 ✓ (recvComm != NULL) → while 条件: sendComm==NULL || recvComm==NULL → recvComm 非 NULL,accept() 不再被调用 rank1 的 connect(self) 还卡在 StateSend/StateConnecting → 需要有人 accept() 自己发过去的 QP info → 但 while 循环里 recvComm 已非 NULL,不会再调 accept() → sendComm 永远是 NULL → while(sendComm==NULL || recvComm==NULL) 永远成立 → rank1 无限循环,sendComm 卡死 ← HANG - sanitizer 跨机给出的 error 分别有:
- 两边 signal 计数会乱,改成发端统计好有多少signal,通知收端,收端直接只下一次 wait 操作。 ⬇️
- 在flagcxHeteroWaitSignal内加了D2H的拷贝,把当前收端 current signal 打印出来和 sender 发过来的signal 做对比, 观察到每次连续 runtest的时候第二次测试 recv 端需要 194 个,但是每次卡在 180个左右就再也等不到了,prefill 侧 log 看到 ibrc 打印FLAGCX WARN NET/IB : unable to allocate requests和FLAGCX WARN flagcxRmaProgressThread: op failed peer=1 type=1 res=3
当rma 的 proxyThread 执行的时候,
flagcxRmaProgressThread去调用 ibrc_adaptoe封装的flagcxIbIputSignal,这里当并发大的时候就会返回 flagcxInternalError,然后flagcxRmaProgressThread检查不是 flagcxSuccess 就会直接 free 这个 wr。。。。。
所以问题就是如果256 个 slots 都不是空的时刻,新进来的请求就会被flagcxRmaProgressThread ← 从 pending 取出 desc └─ netAdaptor->iputSignal() ← IB adaptor 层 └─ flagcxIbGetRequest() ← 从 reqs[256] 里找一个 UNUSED slot ← 找到 → 设 type=IPUT, 返回指针存到 desc->request ← 找不到 → "unable to allocate requests", 返回 flagcxInternalError └─ 成功后: desc 挂到 inProgress 链表 └─ 后续循环: netAdaptor->test(desc->request) └─ flagcxIbTest → flagcxIbCommonTestDataQp └─ ibv_poll_cq() 收割 CQE └─ events 减到 0 → flagcxIbFreeRequest(r) ← r->type = UNUSED, slot 回收 └─ done=1 → rmaDescComplete(desc) → free(desc)flagcxIbGetRequest函数内的for loop 挡在外面,返回的是flagcxInternalError导致后续的代码直接 free 掉了当前的 desc,因此在这里尝试了不 free,不成功就把当前的 desc 重新enque 到 proxy 链表后,所有
if (res != flagcxSuccess) { WARN(“flagcxRmaProgressThread: op failed peer=%d type=%d res=%d”, p, (int)desc→type, (int)res); __atomic_store_n(&proxy→rmaError, 1, __ATOMIC_RELEASE); free(desc); ```
-
【bug2】tp=2 的 prefill / decode观察到,出现 hang 的时候每一边都另一个 host:ip 服务看不到
Prefill:flagcx_connector.py:554: Pair comm ready (responder/rank=1) ↔ 10.8.2.169:8999 Decode:flagcx_connector.py:575: Pair comm ready (initiator/rank=0) ↔ tcp://10.8.2.168:8999Prefill: (Worker_TP0 pid=167763) [2026-04-15 19:59:53] INFO flagcx_connector.py:510: Registered 96 KV MRs + per-pair signal buffer for pair comm=0x7fb1d4001160 (signal_ptr=0x7fc0315eb400, signal_device=cuda:0, current_device=0) (Worker_TP0 pid=167763) [2026-04-15 19:59:53] INFO flagcx_connector.py:554: Pair comm ready (responder/rank=1) ↔ 10.8.2.169:8998 (Worker_TP1 pid=167764) [2026-04-15 19:59:53] INFO flagcx_connector.py:510: Registered 96 KV MRs + per-pair signal buffer for pair comm=0x7f8c88001160 (signal_ptr=0x7f8c60200000, signal_device=cuda:0, current_device=0) (Worker_TP1 pid=167764) [2026-04-15 19:59:53] INFO flagcx_connector.py:554: Pair comm ready (responder/rank=1) ↔ 10.8.2.169:8999 Decode: INFO flagcx_connector.py:510: Registered 96 KV MRs + per-pair signal buffer for pair comm=0x7fb4e4000ba0 (signal_ptr=0x7fc3515eb000, signal_device=cuda:0, current_device=0) (Worker_TP0 pid=54913) [2026-04-15 19:59:53] INFO flagcx_connector.py:575: Pair comm ready (initiator/rank=0) ↔ tcp://10.8.2.168:8998 (Worker_TP1 pid=54914) [2026-04-15 19:59:53] INFO flagcx_connector.py:510: Registered 96 KV MRs + per-pair signal buffer for pair comm=0x7f48f8000ba0 (signal_ptr=0x7f48d6200000, signal_device=cuda:0, current_device=0) (Worker_TP1 pid=54914) [2026-04-15 19:59:53] INFO flagcx_connector.py:575: Pair comm ready (initiator/rank=0) ↔ tcp://10.8.2.168:8999这里的改动思想很简单,就是 sender 的 work 第一次进来去告诉receiver 我的uid,同时 decode 的 listen 线程提前开始等待这个,一起开始调用commInitRank和_register_kv_for_comm。解决这个 bug2 后在后续测试 bug1 的几十次 vllm serve 都没有出现开头就 hang 的问题了。✅
-
【bug3】优化 flagcxRmaProgressThread性能,现在存在请求多大 size 时性能巨差的性能问题 在看了 nccl 的实现之后,确定核心问题如下:

把 post 和 poll 的过程从一次 loop 推进一个变成多个,带来了 4.5% 左右的提升。但是还是没有解决问题
nccl2.30 内为了进一步让 gin→xxxx 的 oneSide communication 可以 cudaGraph/overlap,所以 sender 也会自己下WriteValue/waitValue 来确保前置的 kernel 完成后才发起put/get 操作。它的过程大致如下:
Launch 线程 GPU Stream Proxy 线程 ──────────── ────────── ────────── enqueue desc[0..3] cuStreamBatchMemOp() → WriteValue(readySeqDev, 1) → WriteValue(readySeqDev, 2) → WriteValue(readySeqDev, 3) → WriteValue(readySeqDev, 4) [GPU kernel 写完 src 后执行↓] readySeqDev=4 readySeq(GDR)=4 4 >= opSeq=1 ✓ → iput → inProgress 4 >= opSeq=2 ✓ → iput → inProgress ... NIC done[0] → doneSeq=1 (RELEASE) doneSeqDev=1 WaitValue(doneSeq≥1)──→ GPU stream 解锁 (后续 kernel 可消费 dst)于是发现可能是我们没有用多个 QP,于是修改下面代码:
# flagcx/adaptor/net/ibrc_adaptor.cc # iputSingal的实现里面拿 qp 的逻辑修改为: int qpIdx = comm->base.qpIndex; comm->base.qpIndex = (qpIdx + 1) % comm->base.nqps; struct flagcxIbQp *qp = &comm->base.qps[qpIdx];16k 输入的场景 300 条 request
- 优化上述 proxyProgress 之后从 209s 到 200 秒
- 给 inputSignal 每次只选 qp0 的代码改成 roundrobin 的选多个 QP 又减少了 20 秒
最终在 wr_list一次挂 256 个 wr 只 doorbell 一次性能最好。于是增加 batchPut 等接口见 flagcx 的 PR461。🎉done
-
【bug4】tpot 奇怪下降(对齐 mooncake
mooncake connector 逻辑 Decode start_load_kv() └─ receive_kv() 通过 ZMQ REQ 请求 Prefill 发送 KV └─ 等 Prefill 回 TRANS_DONE └─ finished_recving_reqs 加入 req_id Prefill _mooncake_sender 线程 └─ 收到请求 → ThreadPool submit _sender_worker() └─ send_kv_to_decode() └─ _send_blocks() ├─ send_meta.ready.wait() ├─ 按连续 block 合并 src_ptrs/dst_ptrs/lengths └─ engine.batch_transfer_sync_write() ← 批量纯 RDMA writeflagcx connector 逻辑 Decode worker └─ start_load_kv() └─ _group_kv_pull() └─ asyncio.run_coroutine_threadsafe(_receive_kv()) └─ _receive_kv() ├─ ZMQ DEALER 发 FlagCXAgentMetadata 给 Prefill ├─ 等 Prefill partial/FINISH response └─ process_ok_reqs() └─ finished_recving_reqs 加入 req_id _flagcx_sender 线程 └─ ROUTER 收 Decode 请求 → ThreadPool submit _sender_worker() └─ _sender_worker() ├─ 第一次 peer: _create_pair_comm() │ ├─ ZMQ 交换 uid │ ├─ flagcxCommInitRank() │ └─ _register_kv_for_comm() └─ _send_kv_to_decode() ├─ 轮询 ready_reqs;没 ready 就 sleep(0.01) ├─ _send_blocks() │ ├─ 按 req 合并连续 block group │ ├─ for layer × K/V MR × group │ │ └─ 按 FLAGCX_CONNECTOR_SLICE_SIZE=65536 切片 │ ├─ 每 256 个 slice flush 一次 flagcxBatchPut() │ └─ 返回 wait_counter_target = pair_info.total_puts ├─ flagcxWaitCounter(comm, wait_counter_target) └─ ZMQ 回 FINISH/CONTINUE 给 Decode观察到 decode 侧 flagcx batch size的变化曲线判断出 flagcx 的传输有极大的问题(打不满 256 的 batch size)
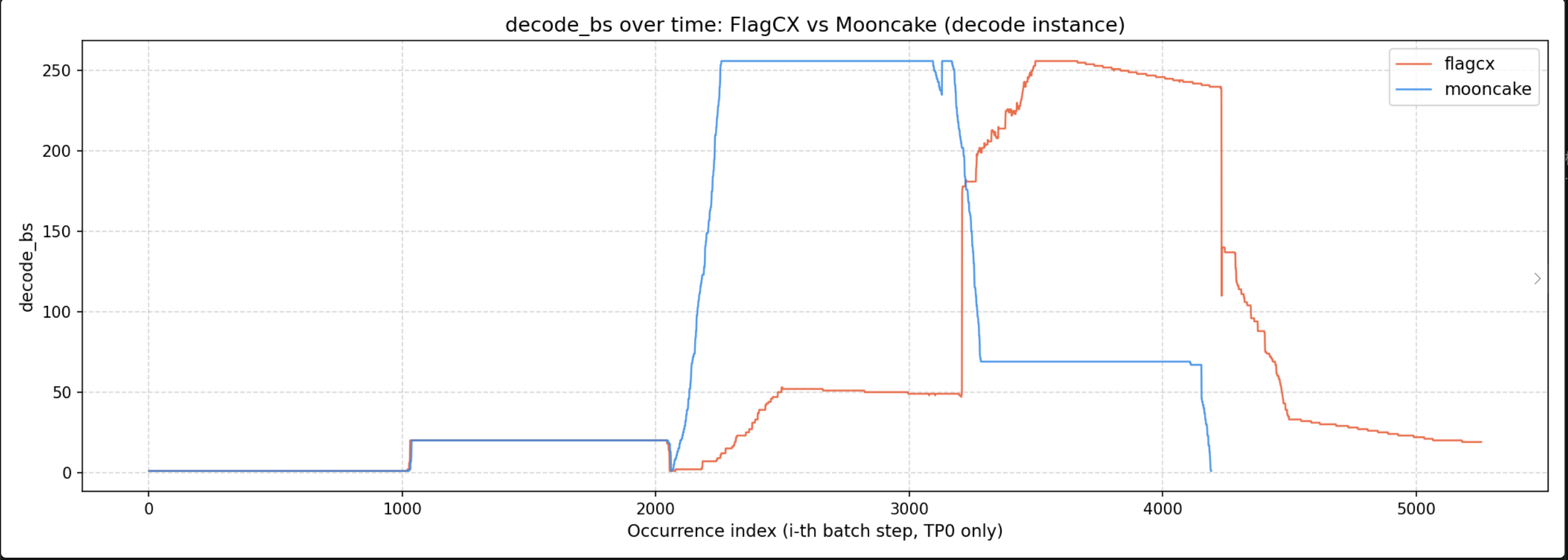
nsys观察到:
- _send_blocks 在 mooncake 内只调用了三次 batch_write_sync
- 在 flagcx 内调用了9600次batchPut,且我们的 9600 次 batchPut 之间都存在一个类似同步的操作(waitCounter)在确保 counter 没有问题。
优化一:connector 侧完全 prefill 阶段不发东西,wait等待,然后发一个大的。
## 原本代码
============ Serving Benchmark Result ============
Successful requests: 325
Failed requests: 0
Request rate configured (RPS): 65.00
Benchmark duration (s): 59.63
Total input tokens: 2662400
Total generated tokens: 332800
Request throughput (req/s): 5.45
Output token throughput (tok/s): 5581.51
Peak output token throughput (tok/s): 7361.00
Peak concurrent requests: 325.00
Total token throughput (tok/s): 50233.57
---------------Time to First Token----------------
Mean TTFT (ms): 17767.51
Median TTFT (ms): 15506.44
P50 TTFT (ms): 15506.44
P90 TTFT (ms): 35392.40
P99 TTFT (ms): 35777.85
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 23.13
Median TPOT (ms): 25.05
P50 TPOT (ms): 25.05
P90 TPOT (ms): 27.34
P99 TPOT (ms): 31.52
---------------Inter-token Latency----------------
Mean ITL (ms): 23.14
Median ITL (ms): 23.71
P50 ITL (ms): 23.71
P90 ITL (ms): 27.95
P99 ITL (ms): 38.76
----------------End-to-end Latency----------------
Mean E2EL (ms): 41428.71
Median E2EL (ms): 43470.07
P50 E2EL (ms): 43470.07
P90 E2EL (ms): 54693.80
P99 E2EL (ms): 55054.24
==================================================
## 去掉 sleep 后
============ Serving Benchmark Result ============
Successful requests: 325
Failed requests: 0
Request rate configured (RPS): 65.00
Benchmark duration (s): 54.55
Total input tokens: 2662400
Total generated tokens: 332800
Request throughput (req/s): 5.96
Output token throughput (tok/s): 6101.36
Peak output token throughput (tok/s): 7765.00
Peak concurrent requests: 325.00
Total token throughput (tok/s): 54912.26
---------------Time to First Token----------------
Mean TTFT (ms): 7590.21
Median TTFT (ms): 213.99
P50 TTFT (ms): 213.99
P90 TTFT (ms): 31412.13
P99 TTFT (ms): 31716.24
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 30.68
Median TPOT (ms): 34.23
P50 TPOT (ms): 34.23
P90 TPOT (ms): 34.48
P99 TPOT (ms): 46.25
---------------Inter-token Latency----------------
Mean ITL (ms): 30.68
Median ITL (ms): 30.92
P50 ITL (ms): 30.92
P90 ITL (ms): 34.07
P99 ITL (ms): 116.63
----------------End-to-end Latency----------------
Mean E2EL (ms): 38979.34
Median E2EL (ms): 35429.52
P50 E2EL (ms): 35429.52
P90 E2EL (ms): 49856.71
P99 E2EL (ms): 50150.66
==================================================
## mooncake
============ Serving Benchmark Result ============
Successful requests: 325
Failed requests: 0
Request rate configured (RPS): 65.00
Benchmark duration (s): 42.76
Total input tokens: 2662400
Total generated tokens: 332800
Request throughput (req/s): 7.60
Output token throughput (tok/s): 7783.21
Peak output token throughput (tok/s): 10242.00
Peak concurrent requests: 325.00
Total token throughput (tok/s): 70048.86
---------------Time to First Token----------------
Mean TTFT (ms): 4711.41
Median TTFT (ms): 198.87
P50 TTFT (ms): 198.87
P90 TTFT (ms): 21675.86
P99 TTFT (ms): 21999.12
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 23.28
Median TPOT (ms): 25.28
P50 TPOT (ms): 25.28
P90 TPOT (ms): 25.54
P99 TPOT (ms): 25.58
---------------Inter-token Latency----------------
Mean ITL (ms): 23.28
Median ITL (ms): 24.06
P50 ITL (ms): 24.06
P90 ITL (ms): 30.97
P99 ITL (ms): 43.02
----------------End-to-end Latency----------------
Mean E2EL (ms): 28530.16
Median E2EL (ms): 26252.75
P50 E2EL (ms): 26252.75
P90 E2EL (ms): 37902.56
P99 E2EL (ms): 37979.00
==================================================优化二:多QP
当前的代码在开 FLAGCX_IB_QPS_PER_CONN是 1 和 2 的时候,性能无变化,说明当前代码不生效,原因我认为就是:
1. Batch 1: 抓 256 个 req,全打到 QP0, 池空
2. proxy 进入 poll-completion → CQ 还没回任何东西 → 阻塞等 QP0 完成
3. QP0 慢(比如某个对端 buffer 落在慢路径,或 PCIe 抖动)→ 池一直空
4. 此时 QP1/QP2/QP3 的 SQ 完全空着,但 proxy 没有请求槽可分配,post 不下去
池子的周期如下:
flagcxIbGetRequest()
→ reqs[i](槽指针)
→ 作为 wr_id 写入 ibv_send_wr / ibv_recv_wr
· 单请求:wr_id = req - base->reqs(下标)
· 多请求:wr_id = Σ idx_j << (j*8)
→ ibv_post_send / ibv_post_recv → HW 执行
→ ibv_poll_cq 拿到 wc.wr_id
→ req_idx = wc.wr_id & 0xff → base->reqs + req_idx 还原 req
→ req->events[i]-- 直到 events[0]==0 && events[1]==0
→ *done=1,flagcxIbFreeRequest 归还槽
额外猜想:mooncake 用了 10 个worker去下 batch_put,然后在底层不同的 batch 能够全并发 ❌ tp0→tp0
int TransferEnginePy::batchTransferSync(
const int max_retry = engine_->numContexts() + 1;
for (int retry = 0; retry < max_retry; ++retry) {
auto batch_id = engine_->allocateBatchID(batch_size); // 全新 batch
engine_->submitTransfer(batch_id, entries);
while (!completed) {
engine_->getBatchTransferStatus(batch_id, status); // 只看自己这个 batch
if (status.s == COMPLETED) return 0; // 不等其他 batch
}
}
)batch输入[req1,req2], 每个 req 是 1024 个 token 的话,是每一层结束调用一次 batchPut(调用 n 层次),还是每个 req的所有层结束调用一次 batchPut一下全给 decode?然后没有传完一个 req1 的完整的所有层的 kv cache的话 decode 是不能直接开始 attention 的还是只要每个 req 的第一层的 kv cache 拿到就可以开始 attention?
- 答:每个请求的每一层都会直接 pass,只会到最后直接一下拿到完整的所有 req 的所有 layer 的 kv cache。
3 test
168/169机器需要让 gpu 内核加载这个 ib 的模块(如果没有的话):
lsmod | grep -i peer
modprobe nvidia_peermem
安装 flagos 的东西:
git clone https://github.com/flagos-ai/vllm-plugin-FL.git
pip install --no-build-isolation -e .
git clone https://github.com/flagos-ai/FlagGems.git
pip install --no-build-isolation -e .剩下的参考:vllm-plugin-FL/examples/disaggregated_serving_xpyd/run_flagcx_connector.md