1. Mooncake Transfer engine
前言
情况一:vllmv0.13.0 内没有 mooncake 的 router.py,需要直接复制我的才能跑,不然会报错 bootstrap 服务端口被占用。
情况二:在测试的时候如果 log 日志里面看到 prefill 给 decode 的 mlx5_10 发数据,QP 无法 RTR(ready to recv),这里需要修改vllm 内mooncake connector 的代码才能正确按照我们的网卡列表正确选择正确的网卡。
在vllm/distributed/kv_transfer/kv_connector/v1/mooncake_connector.py内按照下面的 diff 修改,修改后在 prefill/decode 的启动脚本内指定你机器上可用的 mlx 网卡,我这里已经额外指定为: "kv_connector_extra_config":{"rdma_devices":"mlx5_0,mlx5_1,mlx5_2,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_7"}。
# 改前
ret_value = self.engine.initialize(self.hostname, "P2PHANDSHAKE", "rdma", "")
# 改后
_rdma_devs = vllm_config.kv_transfer_config.kv_connector_extra_config.get("rdma_devices", "")
ret_value = self.engine.initialize(self.hostname, "P2PHANDSHAKE", "rdma", _rdma_devs)启动脚本
参考: https://docs.vllm.ai/en/v0.13.0/features/mooncake_connector_usage/
step1. vllm checkout to v0.13.0 branch
step2. 在每个节点上下载
pip install mooncake-transfer-enginestep3. 在 node1 上:
export NCCL_SOCKET_IFNAME=bond0
export GLOO_SOCKET_IFNAME=bond0
export NCCL_DEBUG=version
export NCCL_IB_HCA==mlx5_0,mlx5_1,mlx5_2,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_7
export MOONCAKE_PROTOCOL=rdma
export MOONCAKE_DEVICE=mlx5_0,mlx5_1,mlx5_2,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_7
export NCCL_NVLS_ENABLE=0
export NCCL_IB_GID_INDEX=3
export VLLM_RPC_TIMEOUT=600000
export VLLM_ENGINE_ITERATION_TIMEOUT_S=600
export VLLM_PLUGINS=""
nohup vllm serve /inspire/hdd/global_public/public_models/Qwen/Qwen3-30B-A3B-Instruct-2507/ \
--host 0.0.0.0 \
--port 20001 \
--tensor-parallel-size 8 \
--seed 1024 \
--max-model-len 66560 \
--max-num-batched-tokens 65536 \
--max-num-seqs 256 \
--served-model-name base_model \
--trust-remote-code \
--kv-cache-dtype fp8 \
--gpu-memory-utilization 0.8 \
--kv-transfer-config \
'{"kv_connector":"MooncakeConnector","kv_role":"kv_producer","kv_connector_extra_config":{"rdma_devices":"mlx5_0,mlx5_1,mlx5_2,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_7"}}' > prefill.log 2>&1 &
step4. 在 node2 上:
export NCCL_SOCKET_IFNAME=bond0
export GLOO_SOCKET_IFNAME=bond0
export NCCL_DEBUG=version
export NCCL_IB_HCA==mlx5_0,mlx5_1,mlx5_2,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_7
export MOONCAKE_PROTOCOL=rdma
export MOONCAKE_DEVICE=mlx5_0,mlx5_1,mlx5_2,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_7
export NCCL_NVLS_ENABLE=0
export NCCL_IB_GID_INDEX=3
export VLLM_RPC_TIMEOUT=600000
export VLLM_ENGINE_ITERATION_TIMEOUT_S=600
export VLLM_PLUGINS=""
nohup vllm serve /inspire/hdd/global_public/public_models/Qwen/Qwen3-30B-A3B-Instruct-2507/ \
--host 0.0.0.0 \
--port 20002 \
--tensor-parallel-size 8 \
--seed 1024 \
--served-model-name base_model \
--max-model-len 66560 \
--max-num-batched-tokens 65536 \
--max-num-seqs 256 \
--trust-remote-code \
--kv-cache-dtype fp8 \
--gpu-memory-utilization 0.8 \
--kv-transfer-config \
'{"kv_connector":"MooncakeConnector","kv_role":"kv_consumer","kv_connector_extra_config":{"rdma_devices":"mlx5_0,mlx5_1,mlx5_2,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_7"}}' > decode.log 2>&1 &step5. 在 node1 上:(在 vllm 0.13.0版本中官方并没有写mooncake 选择 P 和 D 节点的 router.py,所以需要替换为下面的才可以跑:)
# SPDX-License-Identifier: Apache-2.0
# 1P1D disaggregated serving proxy for MooncakeConnector (ZMQ side-channel, no HTTP bootstrap)
#
# Usage:
# python3 router.py \
# --host 0.0.0.0 --port 8000 \
# --prefill http://<prefill_host>:<vllm_port> 8998 \
# --decode http://<decode_host>:<vllm_port>
#
# VLLM_MOONCAKE_BOOTSTRAP_PORT is the ZMQ side-channel BASE port (default 8998).
import argparse
import asyncio
import itertools
import os
import urllib.parse
import uuid
from contextlib import asynccontextmanager
import httpx
from fastapi import FastAPI, HTTPException, Request
from fastapi.responses import StreamingResponse
global_args = None
async def wait_for_prefill_health(prefill_clients, ready):
for client_info in prefill_clients:
while True:
try:
response = await client_info["client"].get("/health")
response.raise_for_status()
break
except Exception as exc:
print(f"Waiting for prefill {client_info['url']}/health: {exc}")
await asyncio.sleep(1)
print(f"Prefill {client_info['url']} is healthy.")
ready.set()
print("All prefill instances are ready.")
@asynccontextmanager
async def lifespan(app):
app.state.prefill_clients = []
app.state.decode_clients = []
app.state.ready = asyncio.Event()
for url, side_channel_port in global_args.prefill:
parsed_url = urllib.parse.urlparse(url)
app.state.prefill_clients.append({
"client": httpx.AsyncClient(
timeout=None, base_url=url,
limits=httpx.Limits(max_connections=None, max_keepalive_connections=None),
),
"url": url,
"remote_host": parsed_url.hostname,
"side_channel_port": side_channel_port,
})
for url in global_args.decode:
app.state.decode_clients.append({
"client": httpx.AsyncClient(
timeout=None, base_url=url,
limits=httpx.Limits(max_connections=None, max_keepalive_connections=None),
),
})
asyncio.create_task(wait_for_prefill_health(app.state.prefill_clients, app.state.ready))
app.state.prefill_iterator = itertools.cycle(range(len(app.state.prefill_clients)))
app.state.decode_iterator = itertools.cycle(range(len(app.state.decode_clients)))
print(f"Got {len(app.state.prefill_clients)} prefill clients and {len(app.state.decode_clients)} decode clients.")
yield
for c in app.state.prefill_clients:
await c["client"].aclose()
for c in app.state.decode_clients:
await c["client"].aclose()
app = FastAPI(lifespan=lifespan)
async def send_to_prefill(prefill_client, endpoint, req_data, request_id):
data = req_data.copy()
data["kv_transfer_params"] = {"do_remote_decode": True, "do_remote_prefill": False}
data["stream"] = False
data["max_tokens"] = 1
if "max_completion_tokens" in data:
data["max_completion_tokens"] = 1
data.pop("stream_options", None)
headers = {"X-Request-Id": request_id}
api_key = os.environ.get("OPENAI_API_KEY", "")
if api_key:
headers["Authorization"] = f"Bearer {api_key}"
try:
response = await prefill_client["client"].post(endpoint, json=data, headers=headers)
response.raise_for_status()
await response.aclose()
except Exception as exc:
print(f"Prefill request {request_id} error: {exc}")
async def stream_from_decode(prefill_client, decode_client, endpoint, req_data, request_id):
data = req_data.copy()
data["kv_transfer_params"] = {
"do_remote_prefill": True,
"do_remote_decode": False,
"remote_host": prefill_client["remote_host"],
"remote_port": prefill_client["side_channel_port"],
}
headers = {"X-Request-Id": request_id}
api_key = os.environ.get("OPENAI_API_KEY", "")
if api_key:
headers["Authorization"] = f"Bearer {api_key}"
async with decode_client["client"].stream("POST", endpoint, json=data, headers=headers) as response:
response.raise_for_status()
async for chunk in response.aiter_bytes():
yield chunk
async def _handle_completions(api, request):
if not app.state.ready.is_set():
raise HTTPException(status_code=503, detail="Service Unavailable")
try:
req_data = await request.json()
request_id = str(uuid.uuid4())
prefill_client = app.state.prefill_clients[next(app.state.prefill_iterator)]
decode_client = app.state.decode_clients[next(app.state.decode_iterator)]
asyncio.create_task(send_to_prefill(prefill_client, api, req_data, request_id))
async def generate():
async for chunk in stream_from_decode(prefill_client, decode_client, api, req_data, request_id):
yield chunk
return StreamingResponse(generate(), media_type="application/json")
except Exception as e:
import sys, traceback
print(f"Error in proxy [{api}]: {e}")
print("".join(traceback.format_exception(*sys.exc_info())))
raise
@app.post("/v1/completions")
async def handle_completions(request: Request):
return await _handle_completions("/v1/completions", request)
@app.post("/v1/chat/completions")
async def handle_chat_completions(request: Request):
return await _handle_completions("/v1/chat/completions", request)
def parse_args():
parser = argparse.ArgumentParser(description="1P1D proxy for MooncakeConnector (ZMQ side-channel)")
parser.add_argument("--port", type=int, default=8000)
parser.add_argument("--host", type=str, default="0.0.0.0")
parser.add_argument("--prefill", nargs="+", action="append", dest="prefill_raw",
metavar=("URL", "ZMQ_PORT"),
help="Prefill URL and ZMQ side-channel base port (= VLLM_MOONCAKE_BOOTSTRAP_PORT, default 8998)")
parser.add_argument("--decode", nargs=1, action="append", dest="decode_raw",
metavar="URL", help="Decode vllm URL")
args = parser.parse_args()
args.prefill = []
for item in (args.prefill_raw or []):
url = item[0]
port = int(item[1]) if len(item) >= 2 else 8998
args.prefill.append((url, port))
args.decode = [item[0] for item in (args.decode_raw or [])]
if not args.prefill:
parser.error("At least one --prefill URL is required.")
if not args.decode:
parser.error("At least one --decode URL is required.")
return args
if __name__ == "__main__":
global_args = parse_args()
import uvicorn
uvicorn.run(app, host=global_args.host, port=global_args.port)step6. 测试
curl -s http://127.0.0.1:8192/v1/completions \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer EMPTY' \
-d '{
"model": "base_model",
"prompt": "你好,介绍一下你自己",
"max_tokens": 128,
"stream": true
}'#!/bin/bash
export NCCL_IB_HCA=mlx5_0,mlx5_1,mlx5_2,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_7
SLEEP_BETWEEN=5
BASE_ARGS="vllm bench serve \
--base-url http://10.254.12.102:8000 \
--endpoint /v1/completions \
--model /inspire/hdd/global_public/public_models/Qwen/Qwen3-30B-A3B-Instruct-2507/ \
--served-model-name base_model \
--dataset-name random \
--percentile-metrics ttft,tpot,itl,e2el \
--metric-percentiles 50,90,99"
run_test() {
local input_len=$1
local output_len=$2
local rps=$3
local num_prompts=$(( rps * 5 ))
echo "========================================"
echo "Testing input=${input_len} output=${output_len} rps=${rps} num_prompts=${num_prompts}"
echo "========================================"
$BASE_ARGS \
--random-input-len "$input_len" \
--random-output-len "$output_len" \
--request-rate "$rps" \
--num-prompts "$num_prompts"
echo "Sleeping ${SLEEP_BETWEEN}s before next test..."
sleep "$SLEEP_BETWEEN"
}
# input output rps
run_test 1024 1024 **
run_test 4096 1024 **
run_test 8192 1024 **
run_test 16384 1024 **
run_test 32768 1024 **
echo "All tests done."
# bash test.sh > log/res3.log 2>&1 &# 关掉p或者d
pgrep python | xargs kill -9 && pkill -f python2. Nixl Transfer Engine
启动脚本
参考 https://docs.vllm.ai/en/v0.13.0/features/nixl_connector_usage/#prerequisites
在官方的文档内加了环境变量--enforce-eager,会关掉 cudaGraph,然后导致性能巨低。
step1. pip install nixl
step2. node1 上起 prefill
export NCCL_SOCKET_IFNAME=bond0
export GLOO_SOCKET_IFNAME=bond0
export UCX_NET_DEVICES=all
export VLLM_NIXL_SIDE_CHANNEL_HOST=10.254.12.102
export VLLM_NIXL_SIDE_CHANNEL_PORT=5600
nohup vllm serve /inspire/hdd/global_public/public_models/Qwen/Qwen3-30B-A3B-Instruct-2507/ \
--port 8000 \
--tensor-parallel-size 8 \
--seed 1024 \
--max-model-len 66560 \
--max-num-batched-tokens 65536 \
--max-num-seqs 256 \
--trust-remote-code \
--gpu-memory-utilization 0.8 \
--kv-cache-dtype fp8 \
--kv-transfer-config \
'{"kv_connector":"NixlConnector","kv_role":"kv_producer"}' > prefill.log 2>&1 &step3. node2 上起 decode
export NCCL_SOCKET_IFNAME=bond0
export GLOO_SOCKET_IFNAME=bond0
export UCX_NET_DEVICES=all
export VLLM_NIXL_SIDE_CHANNEL_HOST=10.254.21.132
export VLLM_NIXL_SIDE_CHANNEL_PORT=5601
nohup vllm serve /inspire/hdd/global_public/public_models/Qwen/Qwen3-30B-A3B-Instruct-2507/ \
--port 8000 \
--tensor-parallel-size 8 \
--seed 1024 \
--max-model-len 66560 \
--max-num-batched-tokens 65536 \
--max-num-seqs 256 \
--trust-remote-code \
--gpu-memory-utilization 0.8 \
--kv-cache-dtype fp8 \
--kv-transfer-config \
'{"kv_connector":"NixlConnector","kv_role":"kv_consumer"}' > decode.log 2>&1 &
# --served-model-name base_model \step4. node1 上起 router
python3 router.py \
--port 8192 \
--prefiller-hosts 10.254.12.102 \
--prefiller-ports 8000 \
--decoder-hosts 10.254.21.132 \
--decoder-ports 8000 > router.log 2>&1 &# SPDX-License-Identifier: Apache-2.0
# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
import argparse
import itertools
import logging
import os
import uuid
from contextlib import asynccontextmanager
import httpx
from fastapi import FastAPI, Request
from fastapi.responses import StreamingResponse
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
@asynccontextmanager
async def lifespan(app: FastAPI):
"""
Lifespan context manager to handle startup and shutdown events.
"""
# Startup: Initialize client pools for prefiller and decoder services
app.state.prefill_clients = []
app.state.decode_clients = []
# Create prefill clients
for i, (host, port) in enumerate(global_args.prefiller_instances):
prefiller_base_url = f"http://{host}:{port}/v1"
app.state.prefill_clients.append(
{
"client": httpx.AsyncClient(
timeout=None,
base_url=prefiller_base_url,
limits=httpx.Limits(
max_connections=None,
max_keepalive_connections=None,
),
),
"host": host,
"port": port,
"id": i,
}
)
# Create decode clients
for i, (host, port) in enumerate(global_args.decoder_instances):
decoder_base_url = f"http://{host}:{port}/v1"
app.state.decode_clients.append(
{
"client": httpx.AsyncClient(
timeout=None,
base_url=decoder_base_url,
limits=httpx.Limits(
max_connections=None,
max_keepalive_connections=None,
),
),
"host": host,
"port": port,
"id": i,
}
)
# Initialize round-robin iterators
app.state.prefill_iterator = itertools.cycle(range(len(app.state.prefill_clients)))
app.state.decode_iterator = itertools.cycle(range(len(app.state.decode_clients)))
print(
f"Initialized {len(app.state.prefill_clients)} prefill clients "
f"and {len(app.state.decode_clients)} decode clients."
)
yield
# Shutdown: Close all clients
for client_info in app.state.prefill_clients:
await client_info["client"].aclose()
for client_info in app.state.decode_clients:
await client_info["client"].aclose()
# Update FastAPI app initialization to use lifespan
app = FastAPI(lifespan=lifespan)
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("--port", type=int, default=8000)
# Always use 127.0.0.1 as localhost binds to IPv6 which is blocked on CI
parser.add_argument("--host", type=str, default="127.0.0.1")
# For prefiller instances
parser.add_argument(
"--prefiller-hosts",
"--prefiller-host",
type=str,
nargs="+",
default=["localhost"],
)
parser.add_argument(
"--prefiller-ports", "--prefiller-port", type=int, nargs="+", default=[8100]
)
# For decoder instances
parser.add_argument(
"--decoder-hosts", "--decoder-host", type=str, nargs="+", default=["localhost"]
)
parser.add_argument(
"--decoder-ports", "--decoder-port", type=int, nargs="+", default=[8200]
)
args = parser.parse_args()
# Validate and pair hosts with ports
if len(args.prefiller_hosts) != len(args.prefiller_ports):
raise ValueError(
"Number of prefiller hosts must match number of prefiller ports"
)
if len(args.decoder_hosts) != len(args.decoder_ports):
raise ValueError("Number of decoder hosts must match number of decoder ports")
# Create tuples of (host, port) for each service type
args.prefiller_instances = list(zip(args.prefiller_hosts, args.prefiller_ports))
args.decoder_instances = list(zip(args.decoder_hosts, args.decoder_ports))
return args
def get_next_client(app, service_type: str):
"""
Get the next client in round-robin fashion.
Args:
app: The FastAPI app instance
service_type: Either 'prefill' or 'decode'
Returns:
The next client to use
"""
if service_type == "prefill":
client_idx = next(app.state.prefill_iterator)
return app.state.prefill_clients[client_idx]
elif service_type == "decode":
client_idx = next(app.state.decode_iterator)
return app.state.decode_clients[client_idx]
else:
raise ValueError(f"Unknown service type: {service_type}")
async def send_request_to_service(
client_info: dict, endpoint: str, req_data: dict, request_id: str
):
"""
Send a request to a service using a client from the pool.
"""
req_data = req_data.copy()
req_data["kv_transfer_params"] = {
"do_remote_decode": True,
"do_remote_prefill": False,
"remote_engine_id": None,
"remote_block_ids": None,
"remote_host": None,
"remote_port": None,
}
req_data["stream"] = False
req_data["max_tokens"] = 1
if "max_completion_tokens" in req_data:
req_data["max_completion_tokens"] = 1
if "stream_options" in req_data:
del req_data["stream_options"]
headers = {
"Authorization": f"Bearer {os.environ.get('OPENAI_API_KEY')}",
"X-Request-Id": request_id,
}
response = await client_info["client"].post(
endpoint, json=req_data, headers=headers
)
response.raise_for_status()
# read/consume the response body to release the connection
# otherwise, it would http.ReadError
await response.aread()
return response
async def stream_service_response(
client_info: dict, endpoint: str, req_data: dict, request_id: str
):
"""
Asynchronously stream response from a service using a client from the pool.
"""
headers = {
"Authorization": f"Bearer {os.environ.get('OPENAI_API_KEY')}",
"X-Request-Id": request_id,
}
async with client_info["client"].stream(
"POST", endpoint, json=req_data, headers=headers
) as response:
response.raise_for_status()
async for chunk in response.aiter_bytes():
yield chunk
async def _handle_completions(api: str, request: Request):
try:
req_data = await request.json()
request_id = str(uuid.uuid4())
# Get the next prefill client in round-robin fashion
prefill_client_info = get_next_client(request.app, "prefill")
# Send request to prefill service
response = await send_request_to_service(
prefill_client_info, api, req_data, request_id
)
# Extract the needed fields
response_json = response.json()
await response.aclose() # CRITICAL: Release connection back to pool
kv_transfer_params = response_json.get("kv_transfer_params", {})
if kv_transfer_params:
req_data["kv_transfer_params"] = kv_transfer_params
# Get the next decode client in round-robin fashion
decode_client_info = get_next_client(request.app, "decode")
logger.debug("Using %s %s", prefill_client_info, decode_client_info)
# Stream response from decode service
async def generate_stream():
async for chunk in stream_service_response(
decode_client_info, api, req_data, request_id=request_id
):
yield chunk
return StreamingResponse(generate_stream(), media_type="application/json")
except Exception as e:
import sys
import traceback
exc_info = sys.exc_info()
print(f"Error occurred in disagg prefill proxy server - {api} endpoint")
print(e)
print("".join(traceback.format_exception(*exc_info)))
raise
@app.post("/v1/completions")
async def handle_completions(request: Request):
return await _handle_completions("/completions", request)
@app.post("/v1/chat/completions")
async def handle_chat_completions(request: Request):
return await _handle_completions("/chat/completions", request)
@app.get("/healthcheck")
async def healthcheck():
"""Simple endpoint to check if the server is running."""
return {
"status": "ok",
"prefill_instances": len(app.state.prefill_clients),
"decode_instances": len(app.state.decode_clients),
}
if __name__ == "__main__":
global global_args
global_args = parse_args()
import uvicorn
uvicorn.run(app, host=global_args.host, port=global_args.port)
3. Nccl Send/Recv Transfer Engine
前言
这里依旧存在 https://infrawaves.feishu.cn/wiki/S5NzwFiuni0vbukR0vQceVKKnIe?from=from_copylink 内出现的问题,核心就是如果 request 多,就会爆显存。看了具体的 nccl engine实现:0. vllm 如何使用 nccl 传输 kv cache
确定为 nccl coonector 内的发送端 ncclSend 和接收端 ncclRecv 必须同时发起匹配的操作。接收端必须提前分配好目标 buffer。而P2P NCCL connector 的设计是:先 recv 到一个临时 tensor,等 forward pass 时再 copy 到 KV cache 的正确 block 位置。就导致在并发高,request 多时有可能把这个 nccl connector 自己规划的临时内存撑爆。
启动脚本
同之前跑 deepseek v3.2
4. Qwen3-30B-A3B-Instruct-2507 测试
Mooncake connector
Env: 16 * H200, vllm0.13.0
best practice shell
以下数据分布为:输入[1k, 4k, 8k, 16k, 32k],输出 1k。
说明: 因为不同大小的输入在不同数量的 request 情况下,会由于不同的并发数和 prefill/decode 速度产出不同的结果,控制任何一个变量都会导致另一个指标不佳。为了拿到一个合理情况(即 slo 符合 ttft 在 5 秒内,tpot 在 50ms 内)下最佳性能,内部讨论后确定为:
- slo 条件符合的情况下,二分测试出系统可以承受的最大 rps
- 实际请求数量调整为和并发之间比例大于等于 5,这样两个变量最终可以在不同长度输入下都有一个相同固定值
#!/bin/bash
export NCCL_IB_HCA=mlx5_0,mlx5_1,mlx5_2,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_7
SLEEP_BETWEEN=5
BASE_ARGS="vllm bench serve \
--base-url http://10.254.12.102:8000 \
--endpoint /v1/completions \
--model /inspire/hdd/global_public/public_models/Qwen/Qwen3-30B-A3B-Instruct-2507/ \
--served-model-name base_model \
--dataset-name random \
--percentile-metrics ttft,tpot,itl,e2el \
--metric-percentiles 50,90,99"
run_test() {
local input_len=$1
local output_len=$2
local rps=$3
local num_prompts=$(( rps * 5 ))
echo "========================================"
echo "Testing input=${input_len} output=${output_len} rps=${rps} num_prompts=${num_prompts}"
echo "========================================"
$BASE_ARGS \
--random-input-len "$input_len" \
--random-output-len "$output_len" \
--request-rate "$rps" \
--num-prompts "$num_prompts"
echo "Sleeping ${SLEEP_BETWEEN}s before next test..."
sleep "$SLEEP_BETWEEN"
}
# input output rps
run_test 1024 1024 75
run_test 4096 1024 70
run_test 8192 1024 65
run_test 16384 1024 60
run_test 32768 1024 45
echo "All tests done."
# bash test.sh > log/res5.log 2>&1 &test resaults
========================================
Testing input=1024 output=1024 rps=80 num_prompts=400
========================================
============ Serving Benchmark Result ============
Successful requests: 400
Failed requests: 0
Request rate configured (RPS): 80.00
Benchmark duration (s): 26.64
Total input tokens: 409600
Total generated tokens: 409600
Request throughput (req/s): 15.02
Output token throughput (tok/s): 15377.35
Peak output token throughput (tok/s): 19567.00
Peak concurrent requests: 400.00
Total token throughput (tok/s): 30754.71
---------------Time to First Token----------------
Mean TTFT (ms): 3798.44
Median TTFT (ms): 170.30
P50 TTFT (ms): 170.30
P90 TTFT (ms): 11270.41
P99 TTFT (ms): 12450.50
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 12.59
Median TPOT (ms): 13.05
P50 TPOT (ms): 13.05
P90 TPOT (ms): 13.67
P99 TPOT (ms): 13.75
---------------Inter-token Latency----------------
Mean ITL (ms): 12.59
Median ITL (ms): 12.75
P50 ITL (ms): 12.75
P90 ITL (ms): 15.66
P99 ITL (ms): 28.95
----------------End-to-end Latency----------------
Mean E2EL (ms): 16679.43
Median E2EL (ms): 14140.82
P50 E2EL (ms): 14140.82
P90 E2EL (ms): 22546.26
P99 E2EL (ms): 23369.08
==================================================
========================================
Testing input=4096 output=1024 rps=72 num_prompts=360
========================================
============ Serving Benchmark Result ============
Successful requests: 360
Failed requests: 0
Request rate configured (RPS): 72.00
Benchmark duration (s): 30.95
Total input tokens: 1474560
Total generated tokens: 368640
Request throughput (req/s): 11.63
Output token throughput (tok/s): 11909.66
Peak output token throughput (tok/s): 15227.00
Peak concurrent requests: 360.00
Total token throughput (tok/s): 59548.31
---------------Time to First Token----------------
Mean TTFT (ms): 4014.70
Median TTFT (ms): 115.76
P50 TTFT (ms): 115.76
P90 TTFT (ms): 13839.73
P99 TTFT (ms): 14174.71
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 15.70
Median TPOT (ms): 17.13
P50 TPOT (ms): 17.13
P90 TPOT (ms): 17.46
P99 TPOT (ms): 17.49
---------------Inter-token Latency----------------
Mean ITL (ms): 15.70
Median ITL (ms): 16.37
P50 ITL (ms): 16.37
P90 ITL (ms): 19.41
P99 ITL (ms): 43.13
----------------End-to-end Latency----------------
Mean E2EL (ms): 20077.19
Median E2EL (ms): 17937.31
P50 E2EL (ms): 17937.31
P90 E2EL (ms): 26099.77
P99 E2EL (ms): 26159.16
==================================================
========================================
Testing input=8192 output=1024 rps=65 num_prompts=325
========================================
============ Serving Benchmark Result ============
Successful requests: 325
Failed requests: 0
Request rate configured (RPS): 65.00
Benchmark duration (s): 36.78
Total input tokens: 2662400
Total generated tokens: 332800
Request throughput (req/s): 8.84
Output token throughput (tok/s): 9048.38
Peak output token throughput (tok/s): 12233.00
Peak concurrent requests: 325.00
Total token throughput (tok/s): 81435.46
---------------Time to First Token----------------
Mean TTFT (ms): 3875.87
Median TTFT (ms): 139.76
P50 TTFT (ms): 139.76
P90 TTFT (ms): 17928.26
P99 TTFT (ms): 18312.06
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 20.06
Median TPOT (ms): 21.84
P50 TPOT (ms): 21.84
P90 TPOT (ms): 22.13
P99 TPOT (ms): 22.16
---------------Inter-token Latency----------------
Mean ITL (ms): 20.06
Median ITL (ms): 21.06
P50 ITL (ms): 21.06
P90 ITL (ms): 23.88
P99 ITL (ms): 62.71
----------------End-to-end Latency----------------
Mean E2EL (ms): 24399.70
Median E2EL (ms): 22678.64
P50 E2EL (ms): 22678.64
P90 E2EL (ms): 31907.79
P99 E2EL (ms): 32010.63
==================================================
========================================
Testing input=16384 output=1024 rps=60 num_prompts=300
========================================
============ Serving Benchmark Result ============
Successful requests: 300
Failed requests: 0
Request rate configured (RPS): 60.00
Benchmark duration (s): 45.35
Total input tokens: 4915200
Total generated tokens: 307200
Request throughput (req/s): 6.61
Output token throughput (tok/s): 6773.69
Peak output token throughput (tok/s): 8563.00
Peak concurrent requests: 300.00
Total token throughput (tok/s): 115152.78
---------------Time to First Token----------------
Mean TTFT (ms): 4181.46
Median TTFT (ms): 221.21
P50 TTFT (ms): 221.21
P90 TTFT (ms): 26969.47
P99 TTFT (ms): 27998.35
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 28.73
Median TPOT (ms): 31.55
P50 TPOT (ms): 31.55
P90 TPOT (ms): 31.88
P99 TPOT (ms): 31.93
---------------Inter-token Latency----------------
Mean ITL (ms): 28.74
Median ITL (ms): 30.35
P50 ITL (ms): 30.35
P90 ITL (ms): 33.38
P99 ITL (ms): 94.59
----------------End-to-end Latency----------------
Mean E2EL (ms): 33577.00
Median E2EL (ms): 32605.63
P50 E2EL (ms): 32605.63
P90 E2EL (ms): 40501.84
P99 E2EL (ms): 40596.91
==================================================
========================================
Testing input=32768 output=1024 rps=45 num_prompts=225
========================================
============ Serving Benchmark Result ============
Successful requests: 225
Failed requests: 0
Request rate configured (RPS): 45.00
Benchmark duration (s): 54.76
Total input tokens: 7372800
Total generated tokens: 230400
Request throughput (req/s): 4.11
Output token throughput (tok/s): 4207.47
Peak output token throughput (tok/s): 4806.00
Peak concurrent requests: 225.00
Total token throughput (tok/s): 138846.64
---------------Time to First Token----------------
Mean TTFT (ms): 412.94
Median TTFT (ms): 430.55
P50 TTFT (ms): 430.55
P90 TTFT (ms): 521.72
P99 TTFT (ms): 584.32
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 49.17
Median TPOT (ms): 49.38
P50 TPOT (ms): 49.38
P90 TPOT (ms): 49.87
P99 TPOT (ms): 49.93
---------------Inter-token Latency----------------
Mean ITL (ms): 49.25
Median ITL (ms): 47.91
P50 ITL (ms): 47.91
P90 ITL (ms): 51.39
P99 ITL (ms): 134.41
----------------End-to-end Latency----------------
Mean E2EL (ms): 50717.00
Median E2EL (ms): 50850.67
P50 E2EL (ms): 50850.67
P90 E2EL (ms): 51497.46
P99 E2EL (ms): 51594.59
==================================================
Nixl Connector
best practice shell
#!/bin/bash
export NCCL_IB_HCA=mlx5_0,mlx5_1,mlx5_2,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_7
SLEEP_BETWEEN=5
BASE_ARGS="vllm bench serve \
--base-url http://127.0.0.1:8192 \
--endpoint /v1/completions \
--model /inspire/hdd/global_public/public_models/Qwen/Qwen3-30B-A3B-Instruct-2507/ \
--dataset-name random \
--percentile-metrics ttft,tpot,itl,e2el \
--metric-percentiles 50,90,99"
run_test() {
local input_len=$1
local output_len=$2
local rps=$3
local num_prompts=$(( rps * 5 ))
echo "========================================"
echo "Testing input=${input_len} output=${output_len} rps=${rps} num_prompts=${num_prompts}"
echo "========================================"
$BASE_ARGS \
--random-input-len "$input_len" \
--random-output-len "$output_len" \
--request-rate "$rps" \
--num-prompts "$num_prompts"
echo "Sleeping ${SLEEP_BETWEEN}s before next test..."
sleep "$SLEEP_BETWEEN"
}
# input output rps
run_test 1024 1024 57
run_test 4096 1024 57
run_test 8192 1024 57
run_test 16384 1024 56
run_test 32768 1024 30
echo "All tests done."
# bash test.sh > log/test3.log 2>&1 &test restults
# 使用的自己的满足 slo 下的最大 optput token 的数据
========================================
Testing input=1024 output=1024 rps=80 num_prompts=400
========================================
============ Serving Benchmark Result ============
Successful requests: 400
Failed requests: 0
Request rate configured (RPS): 80.00
Benchmark duration (s): 26.60
Total input tokens: 409600
Total generated tokens: 409600
Request throughput (req/s): 15.04
Output token throughput (tok/s): 15396.34
Peak output token throughput (tok/s): 19726.00
Peak concurrent requests: 400.00
Total token throughput (tok/s): 30792.67
---------------Time to First Token----------------
Mean TTFT (ms): 3831.97
Median TTFT (ms): 175.12
P50 TTFT (ms): 175.12
P90 TTFT (ms): 11221.28
P99 TTFT (ms): 12513.61
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 12.58
Median TPOT (ms): 13.17
P50 TPOT (ms): 13.17
P90 TPOT (ms): 13.65
P99 TPOT (ms): 13.69
---------------Inter-token Latency----------------
Mean ITL (ms): 12.58
Median ITL (ms): 12.12
P50 ITL (ms): 12.12
P90 ITL (ms): 16.12
P99 ITL (ms): 31.89
----------------End-to-end Latency----------------
Mean E2EL (ms): 16706.11
Median E2EL (ms): 14136.31
P50 E2EL (ms): 14136.31
P90 E2EL (ms): 22475.27
P99 E2EL (ms): 23397.91
==================================================
========================================
Testing input=4096 output=1024 rps=72 num_prompts=360
========================================
============ Serving Benchmark Result ============
Successful requests: 360
Failed requests: 0
Request rate configured (RPS): 72.00
Benchmark duration (s): 30.76
Total input tokens: 1474560
Total generated tokens: 368640
Request throughput (req/s): 11.70
Output token throughput (tok/s): 11982.57
Peak output token throughput (tok/s): 15596.00
Peak concurrent requests: 360.00
Total token throughput (tok/s): 59912.85
---------------Time to First Token----------------
Mean TTFT (ms): 3985.90
Median TTFT (ms): 125.12
P50 TTFT (ms): 125.12
P90 TTFT (ms): 13974.44
P99 TTFT (ms): 15191.15
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 15.54
Median TPOT (ms): 16.91
P50 TPOT (ms): 16.91
P90 TPOT (ms): 17.21
P99 TPOT (ms): 17.23
---------------Inter-token Latency----------------
Mean ITL (ms): 15.54
Median ITL (ms): 16.00
P50 ITL (ms): 16.00
P90 ITL (ms): 19.15
P99 ITL (ms): 47.55
----------------End-to-end Latency----------------
Mean E2EL (ms): 19883.20
Median E2EL (ms): 17725.83
P50 E2EL (ms): 17725.83
P90 E2EL (ms): 26257.98
P99 E2EL (ms): 27087.53
==================================================
========================================
Testing input=8192 output=1024 rps=65 num_prompts=325
========================================
============ Serving Benchmark Result ============
Successful requests: 325
Failed requests: 0
Request rate configured (RPS): 65.00
Benchmark duration (s): 37.05
Total input tokens: 2662400
Total generated tokens: 332800
Request throughput (req/s): 8.77
Output token throughput (tok/s): 8981.60
Peak output token throughput (tok/s): 12271.00
Peak concurrent requests: 325.00
Total token throughput (tok/s): 80834.36
---------------Time to First Token----------------
Mean TTFT (ms): 3985.14
Median TTFT (ms): 185.06
P50 TTFT (ms): 185.06
P90 TTFT (ms): 18310.46
P99 TTFT (ms): 19610.50
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 20.15
Median TPOT (ms): 21.85
P50 TPOT (ms): 21.85
P90 TPOT (ms): 22.28
P99 TPOT (ms): 22.30
---------------Inter-token Latency----------------
Mean ITL (ms): 20.15
Median ITL (ms): 20.98
P50 ITL (ms): 20.98
P90 ITL (ms): 23.81
P99 ITL (ms): 68.88
----------------End-to-end Latency----------------
Mean E2EL (ms): 24600.52
Median E2EL (ms): 22777.14
P50 E2EL (ms): 22777.14
P90 E2EL (ms): 32284.57
P99 E2EL (ms): 33075.46
==================================================
========================================
Testing input=16384 output=1024 rps=60 num_prompts=300
========================================
============ Serving Benchmark Result ============
Successful requests: 300
Failed requests: 0
Request rate configured (RPS): 60.00
Benchmark duration (s): 45.68
Total input tokens: 4915200
Total generated tokens: 307200
Request throughput (req/s): 6.57
Output token throughput (tok/s): 6724.98
Peak output token throughput (tok/s): 8595.00
Peak concurrent requests: 300.00
Total token throughput (tok/s): 114324.70
---------------Time to First Token----------------
Mean TTFT (ms): 4313.98
Median TTFT (ms): 303.75
P50 TTFT (ms): 303.75
P90 TTFT (ms): 26941.45
P99 TTFT (ms): 29076.52
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 28.89
Median TPOT (ms): 31.71
P50 TPOT (ms): 31.71
P90 TPOT (ms): 32.02
P99 TPOT (ms): 32.05
---------------Inter-token Latency----------------
Mean ITL (ms): 28.91
Median ITL (ms): 30.23
P50 ITL (ms): 30.23
P90 ITL (ms): 33.93
P99 ITL (ms): 100.18
----------------End-to-end Latency----------------
Mean E2EL (ms): 33865.16
Median E2EL (ms): 32897.35
P50 E2EL (ms): 32897.35
P90 E2EL (ms): 40560.08
P99 E2EL (ms): 41462.42
==================================================
========================================
Testing input=32768 output=1024 rps=35 num_prompts=175
========================================
============ Serving Benchmark Result ============
Successful requests: 175
Failed requests: 0
Request rate configured (RPS): 35.00
Benchmark duration (s): 53.38
Total input tokens: 5734400
Total generated tokens: 179200
Request throughput (req/s): 3.28
Output token throughput (tok/s): 3356.83
Peak output token throughput (tok/s): 3858.00
Peak concurrent requests: 175.00
Total token throughput (tok/s): 110775.28
---------------Time to First Token----------------
Mean TTFT (ms): 846.18
Median TTFT (ms): 538.78
P50 TTFT (ms): 538.78
P90 TTFT (ms): 2006.68
P99 TTFT (ms): 3813.76
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 47.02
Median TPOT (ms): 47.70
P50 TPOT (ms): 47.70
P90 TPOT (ms): 48.23
P99 TPOT (ms): 48.26
---------------Inter-token Latency----------------
Mean ITL (ms): 47.05
Median ITL (ms): 46.53
P50 ITL (ms): 46.53
P90 ITL (ms): 48.28
P99 ITL (ms): 135.85
----------------End-to-end Latency----------------
Mean E2EL (ms): 48952.46
Median E2EL (ms): 49209.38
P50 E2EL (ms): 49209.38
P90 E2EL (ms): 49837.61
P99 E2EL (ms): 49912.54
==================================================Nccl Connector
待定
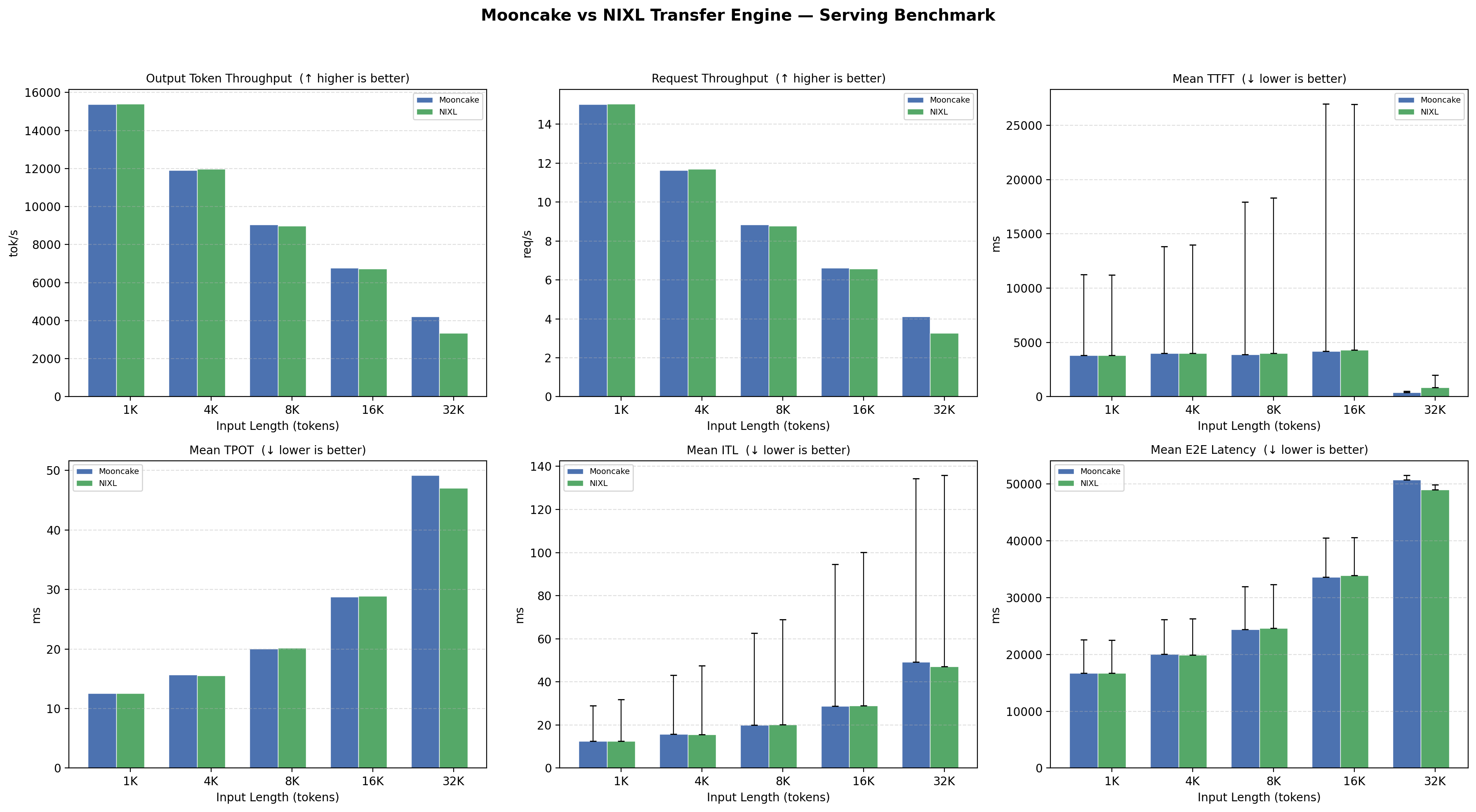
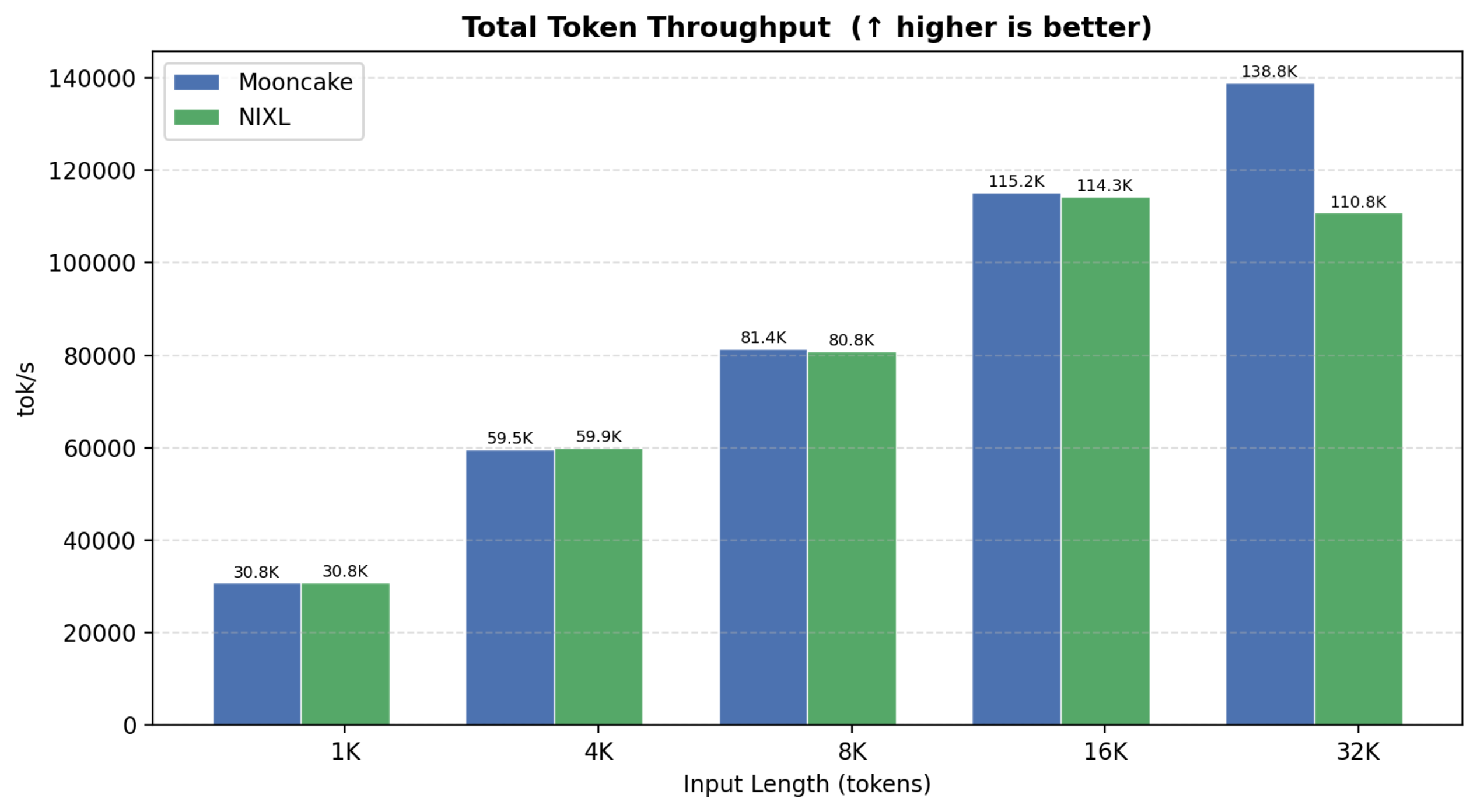
5. 结论
- 吞吐量:NIXL(own RPS) 在 1K~8K 输入下甚至略胜 Mooncake(output TPS 高约 2-5%),32K 处 Mooncake 仍领先约 20%
- 延迟:TPOT / ITL 三者几乎持平;TTFT 在 32K 处 Mooncake 优势明显(461ms vs 2779ms)
- Total Token Throughput:1K~16K 基本打平,32K 处 Mooncake 137.5K vs NIXL 129K
- nccl connector 存在爆显存的问题,看了源码后发现是因为:nccl 在收端起个线程来主导 Prefill 端发 send,每次告诉 p 端之前自己torch.empty()先开一块内存当 send 的 dst address,收完之后又从这个内存拷贝到 kvcache 内。
6. profiler
没网机器下载 nsys 的指令:
cd /inspire/hdd/global_user/huxiaohe-p-huxiaohe/liuda/profiler
chmod +x NsightSystems-linux-public-2026.2.1.210-3763964.run
./NsightSystems-linux-public-2026.2.1.210-3763964.run --accept --quiet
echo 'export PATH=/opt/nvidia/nsight-systems/2026.2.1/bin:$PATH' >> ~/.bashrc
source ~/.bashrc
nsys --version首先,nsys 只能抓到自己这个 rank 的日志,且机间的 put 操作是 cpu 侧下的单边通讯,所以在分析 kv cache 传输的时候需要增加 nvtx 打点。