SM Free & Overlap
SM Free & Overlap is VCCL’s innovative feature that ensures P2P communication operations do not occupy GPU Streaming Multiprocessor (SM) resources, achieving true overlap between communication and computation, significantly improving GPU utilization and training efficiency.
Feature Overview
What is SM Free?
In traditional NCCL implementations, communication operations typically require GPU SM resources to execute kernel functions, which competes with computational tasks for SM resources, leading to:
- Resource Competition: Communication and computation compete for SM resources
- Pseudo Overlap: Appears parallel but actually executes serially
- Reduced Efficiency: Decreased GPU utilization
VCCL’s SM Free mode achieves true overlap through the following technologies:
- Dedicated Communication Path: Communication operations use Memcpy path instead of kernels
- Zero SM Occupation: Communication consumes no SM resources
- True Parallelism: P2P communication and computation can execute completely in parallel through higher bandwidth kernel-free zerocopy mode
How It Works
Technical Architecture
Traditional Mode:
GPU SM ←→ [Compute Kernel] ←Competition→ [Communication Kernel]
SM Free Mode:
GPU SM ←→ [Compute Kernel]
GPU DMA ←→ [Communication Hardware] (Independent Path)
Training Performance Testing
Overview
Regression testing for training performance improvement using VCCL zerocopy.
Preparation
Patch Explanation: We have added support for batched isend/irecv operations in Megatron training to ensure that pipeline parallel (PP) communication does not leave any rank stuck in a pending communication state.
In the original implementation, each communication round consists of a single send and a single receive, but these operations may occur across different groupEnd boundaries. Without batched P2P communication, this behavior is fatal for the SM-free VCCL backend: if a send in comm1 is issued asynchronously by the CPU before its corresponding recv is posted, the receive will never be matched or completed, leading to a deadlock.
By batching isend/irecv, we guarantee that sends and receives are aligned across communication groups, eliminating the risk of unmatched operations and ensuring safe and efficient pipeline parallel communication under VCCL.
Megatron Code Setup:
git clone https://github.com/NVIDIA/Megatron-LM.git
cd Megatron-LM
git checkout core_v0.13.0
# Apply the patch after downloading, this patch is located in `VCCL/asset/Megatron-change.patch`
git apply ./VCCL/asset/Megatron-change.patchTesting Configuration
To obtain the SM-free zerocopy performance benefits, please configure and use the following environment variables step by step as shown below.
Training Arguments
Add --batch-p2p-communication option in the model configuration file to enable P2P batch functionality:
TRAINING_ARGS="
--micro-batch-size $MICRO_BATCH_SIZE \
--global-batch-size $GLOBAL_BATCH_SIZE \
--tensor-model-parallel-size $TP_SIZE \
--pipeline-model-parallel-size $PP_SIZE \
--num-layers-per-virtual-pipeline-stage 5 \
--use-distributed-optimizer \
# Optional parameter for VCCL zerocopy dense model scenarios, if enable account-for-loss-in-pipeline-split, need to NLAYES-1.
# --account-for-loss-in-pipeline-split \
--batch-p2p-communication \
--recompute-granularity selective \
"Output Arguments
OUTPUT_ARGS="
--log-interval 1 \
--eval-iters 4 \
--eval-interval 10000 \
--save-interval $SAVE_INTERVAL \
--log-throughput \
--timing-log-level 0 \
--log-timers-to-tensorboard \
--log-memory-to-tensorboard \
--seed 1024 \
"We use --num-layers-per-virtual-pipeline-stage to ensure 1F1B interleaving, and set --timing-log-level 0 to avoid excessive cudaDeviceSynchronize-style hard synchronizations.
Parallelism Configuration
Set training parameters appropriately to ensure PP communication groups span across machines:
- For server counts that are multiples of 4, set TP=2 and PP=4
- For PP=6, recommend: 6, 12, 18, 24 machines
- For PP=4, recommend: 4, 8, 12, 16 machines
Environment Variables for SM Free Zerocopy
Enable the following environment variables in MPI scripts for improved training TFLOPS:
-x NCCL_PASS_SM=1 \
-x NCCL_PXN_DISABLE=1 \
# NCCL_PSM_FORCE_ZEROCOPY requires NCCL_PASS_SM to be enabled
# If only using kernel-free mode, NCCL_PSM_FORCE_ZEROCOPY is not required
-x NCCL_PSM_FORCE_ZEROCOPY=1 \
-x NCCL_ENABLE_FAULT_TOLERANCE=0 \Please re-check that these variables are present in your mpi.sh (or MPI launch command). Missing or misconfigured values may disable SM-free zerocopy or reduce communication–computation overlap. You can refer to our Example training shell below to train the complete parameters of the 314B model on the cluster.
Example training shell
mpi.sh
#! /bin/bash
TIMESTAMP=$(date +'%Y.%m.%d-%H:%M:%S')
NET_DEVICE="bond0"
MLP_GPU=8
MLP_MPI_HOSTFILE=$2
MLP_WORKER_0_PORT=29500
MLP_WORKER_NUM=$3
source $1
mkdir -p logs/${EXP_NAME}
mpirun -np $((MLP_WORKER_NUM * MLP_GPU)) \
--hostfile ${MLP_MPI_HOSTFILE} \
--allow-run-as-root \
--output-filename logs/${TIMESTAMP} \
--mca oob_tcp_if_include ${NET_DEVICE} \
-x NCCL_DEBUG=Version \
-x PATH \
-x MASTER_ADDR=$(cat $MLP_MPI_HOSTFILE | head -n 1 | sed -s 's/slots=8//g') \
-x MASTER_PORT=${MLP_WORKER_0_PORT} \
-x GLOO_SOCKET_IFNAME=${NET_DEVICE} \
-x NCCL_SOCKET_IFNAME=${NET_DEVICE} \
-x LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/inspire/hdd/global_user/liuda/vccl/build/lib \
-x NCCL_IB_HCA="mlx5_0:1,mlx5_1:1,mlx5_2:1,mlx5_3:1,mlx5_4:1,mlx5_5:1,mlx5_6:1,mlx5_7:1" \
-x NCCL_IB_TIMEOUT=25 \
-x NCCL_IB_RETRY_CNT=255 \
-x NCCL_IB_QPS_PER_CONNECTION=8 \
-x NCCL_ENABLE_FAULT_TOLERANCE=0 \
-x UCX_NET_DEVICES=bond0 \
-x NCCL_CUMEM_ENABLE=1 \
-x NCCL_IB_PCI_RELAXED_ORDERING=1 \
-x UCX_TLS=tcp,self \
-x NCCL_IB_TC=186 \
-x NCCL_NET_GDR_LEVEL=1 \
-x NCCL_PASS_SM=1 \
-x NCCL_IB_GID_INDEX=3 \
-x NCCL_NVLS_ENABLE=0 \
-x CUDA_DEVICE_MAX_CONNECTIONS=1 \
-x NCCL_PXN_DISABLE=1 \
-x NCCL_PSM_FORCE_ZEROCOPY=1 \
python ${script_path} ${gpt_options} 2>&1 | tee logs/${EXP_NAME}/output_${TIMESTAMP}.logmodel-314b.sh
#!/bin/bash
VOCAB_FILE=./train-data/data/gpt2-vocab.json
MERGE_FILE=./train-data/data/gpt2-merges.txt
DATA_PATH=./train-data/data/CodeData-gpt2_text_document
EXP_NAME="314B"
MICRO_BATCH_SIZE=1
GLOBAL_BATCH_SIZE=$((MLP_WORKER_NUM * 8 * 8))
TP_SIZE=8
PP_SIZE=8
NHIDDEN=16384
NLAYERS=95
NHEADS=128
SEQ_LEN=4096
SAVE_INTERVAL=10000
script_path="pretrain_gpt.py"
TARGET_VOCAB=131072
OPTIMIZER_ARGS="
--optimizer adam \
--adam-beta1 0.9 \
--adam-beta2 0.95 \
--adam-eps 1e-8 \
--lr 1.5e-4 \
--min-lr 1.0e-5 \
--lr-decay-style cosine \
--train-iters 10000
--lr-decay-iters 9000 \
--lr-warmup-fraction .01 \
--clip-grad 1.0 \
--weight-decay 1e-2 \
--hidden-dropout 0.0 \
--attention-dropout 0.0 \
--initial-loss-scale 65536 \
"
MODEL_ARGS="
--bf16 \
--num-layers $NLAYERS \
--hidden-size $NHIDDEN \
--seq-length $SEQ_LEN \
--tokenizer-type GPT2BPETokenizer \
--max-position-embeddings $SEQ_LEN \
--num-attention-heads $NHEADS \
--disable-bias-linear \
--swiglu \
--use-flash-attn \
--transformer-impl transformer_engine \
--untie-embeddings-and-output-weights \
--position-embedding-type rope \
--no-position-embedding \
--normalization RMSNorm \
--use-mcore-models \
--manual-gc \
--sequence-parallel \
"
TRAINING_ARGS="
--micro-batch-size $MICRO_BATCH_SIZE \
--global-batch-size $GLOBAL_BATCH_SIZE \
--tensor-model-parallel-size $TP_SIZE \
--pipeline-model-parallel-size $PP_SIZE \
--use-distributed-optimizer \
--recompute-granularity selective \
--batch-p2p-communication \
--account-for-loss-in-pipeline-split \
--num-layers-per-virtual-pipeline-stage 4 \
--make-vocab-size-divisible-by $((TARGET_VOCAB / TP_SIZE)) \
"
# --account-for-embedding-in-pipeline-split \
DATA_ARGS="
--data-path $DATA_PATH \
--vocab-file $VOCAB_FILE \
--merge-file $MERGE_FILE \
--split 949,50,1 \
"
OUTPUT_ARGS="
--log-interval 1 \
--eval-iters 10 \
--eval-interval 1000 \
--save-interval $SAVE_INTERVAL \
--log-throughput \
--timing-log-level 0 \
--log-timers-to-tensorboard \
--log-memory-to-tensorboard \
"
gpt_options="
$MODEL_ARGS \
$TRAINING_ARGS \
$OPTIMIZER_ARGS \
$DATA_ARGS \
$OUTPUT_ARGS \
--distributed-timeout-minutes 60 \
--init-method-std 0.01 \
"Performance Benefits
- True Communication-Computation Overlap: Communication operations don’t compete with computation for SM resources
- Higher Throughput: Zerocopy mode provides higher bandwidth for P2P communication
- Improved Training Efficiency: Better GPU utilization leads to faster training convergence
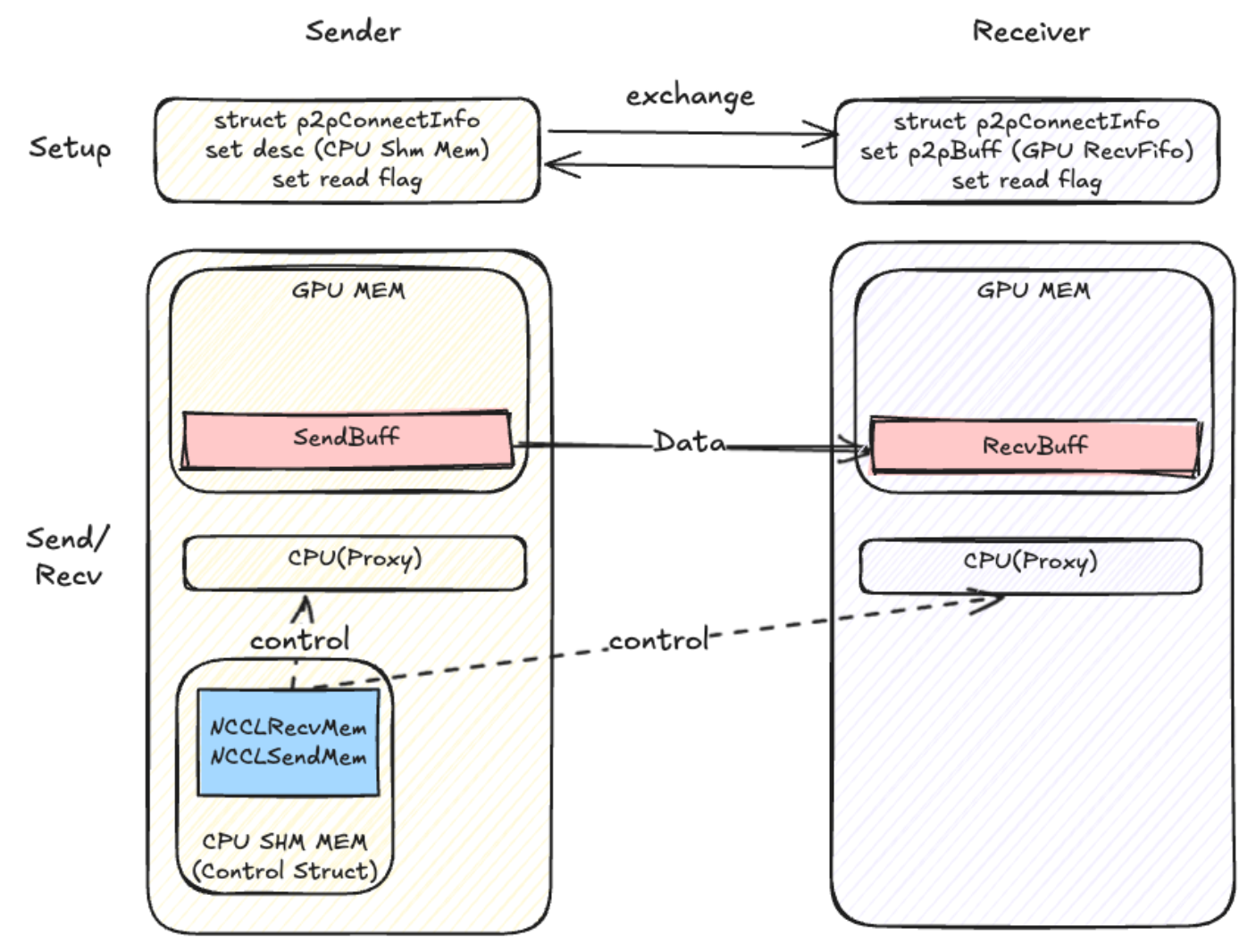
co-design
Registered buffers were introduced for two reasons. First, to achieve zero-copy, optimize latency, and save resources. Second, using zero-copy avoids multiple send/recv operations during the send/recv phase.
Net Transport
Origin
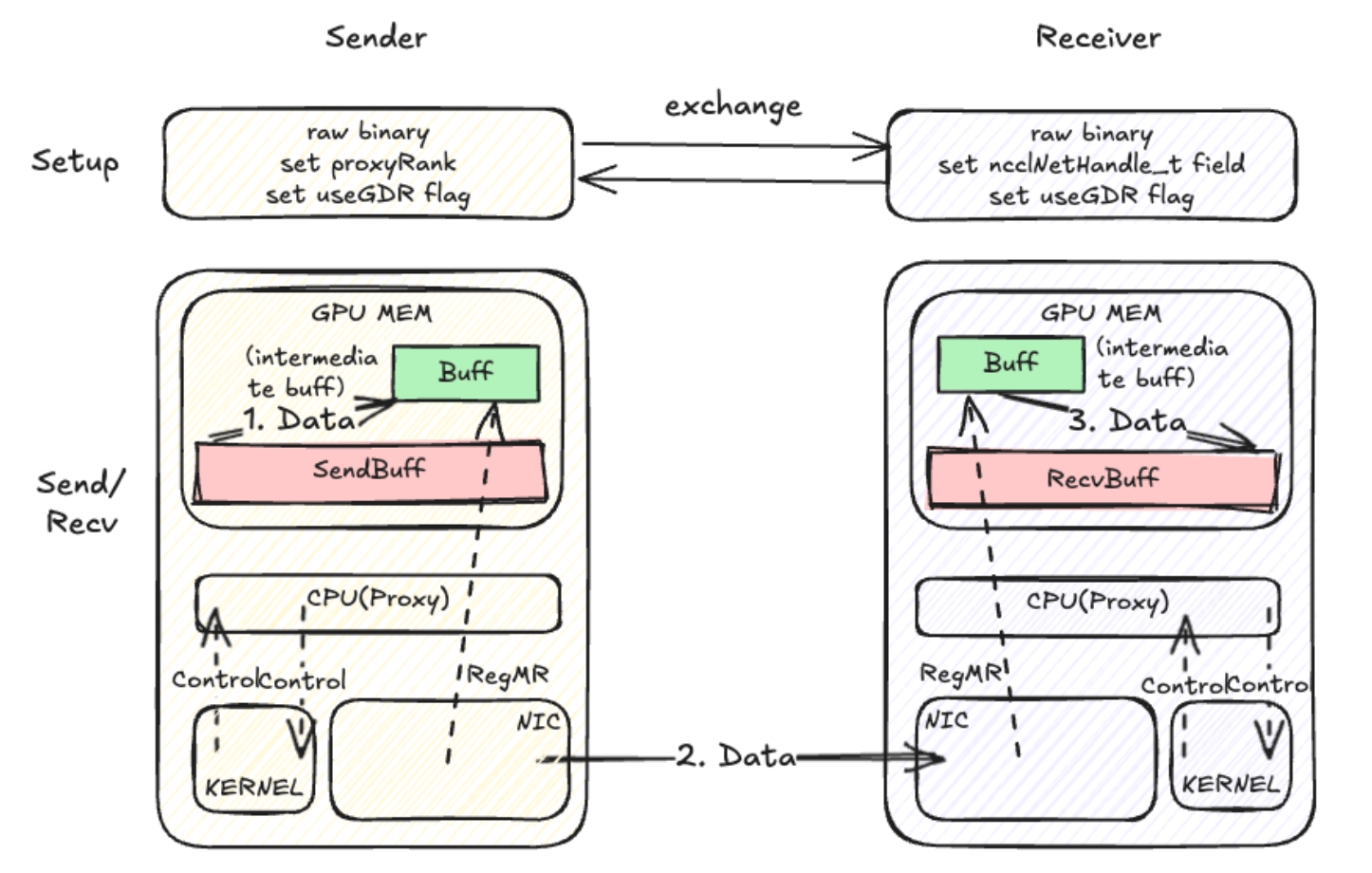 SM-Free
SM-Free
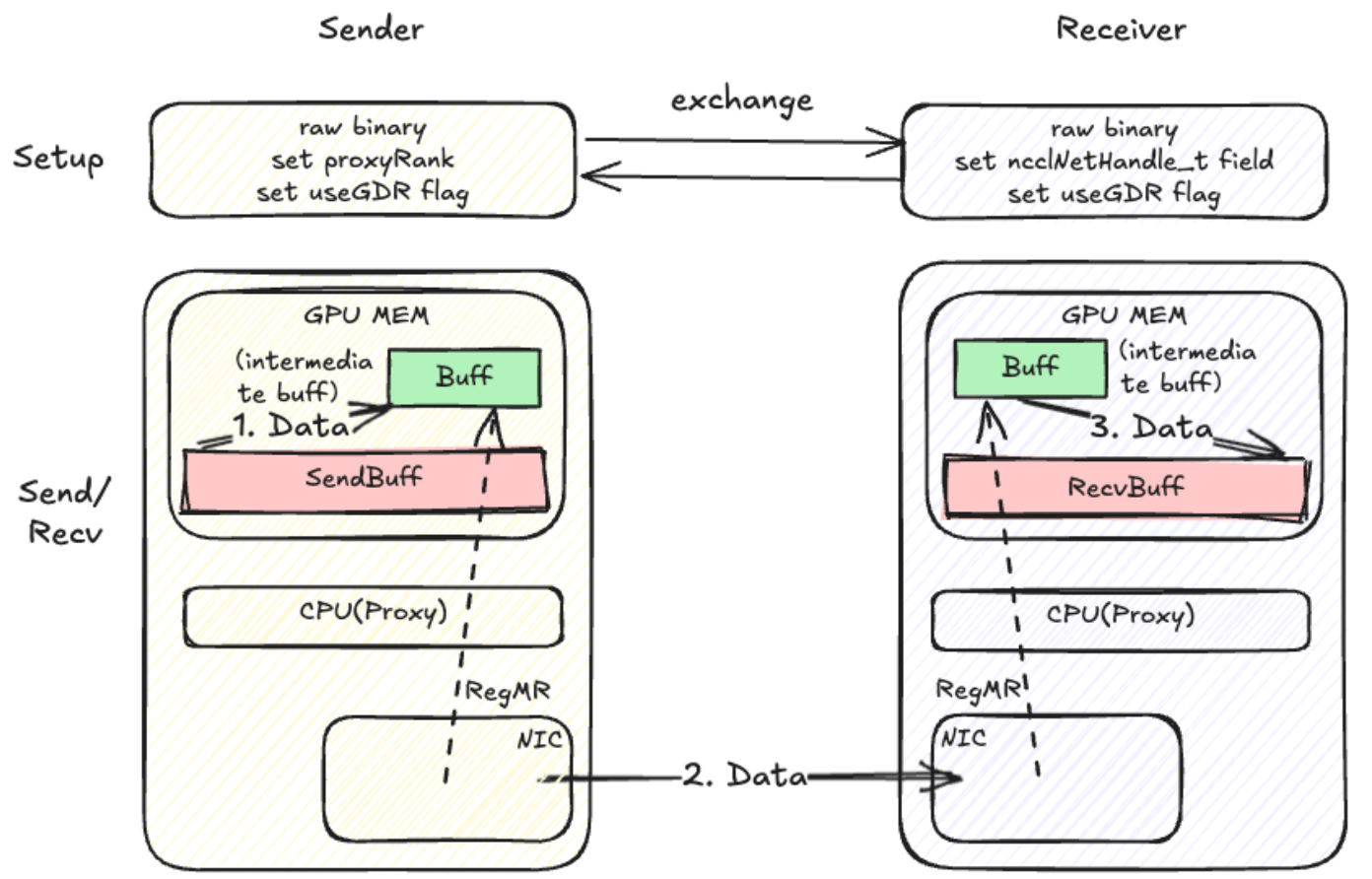 SM-Free with Register buffer(Zerocopy)
SM-Free with Register buffer(Zerocopy)
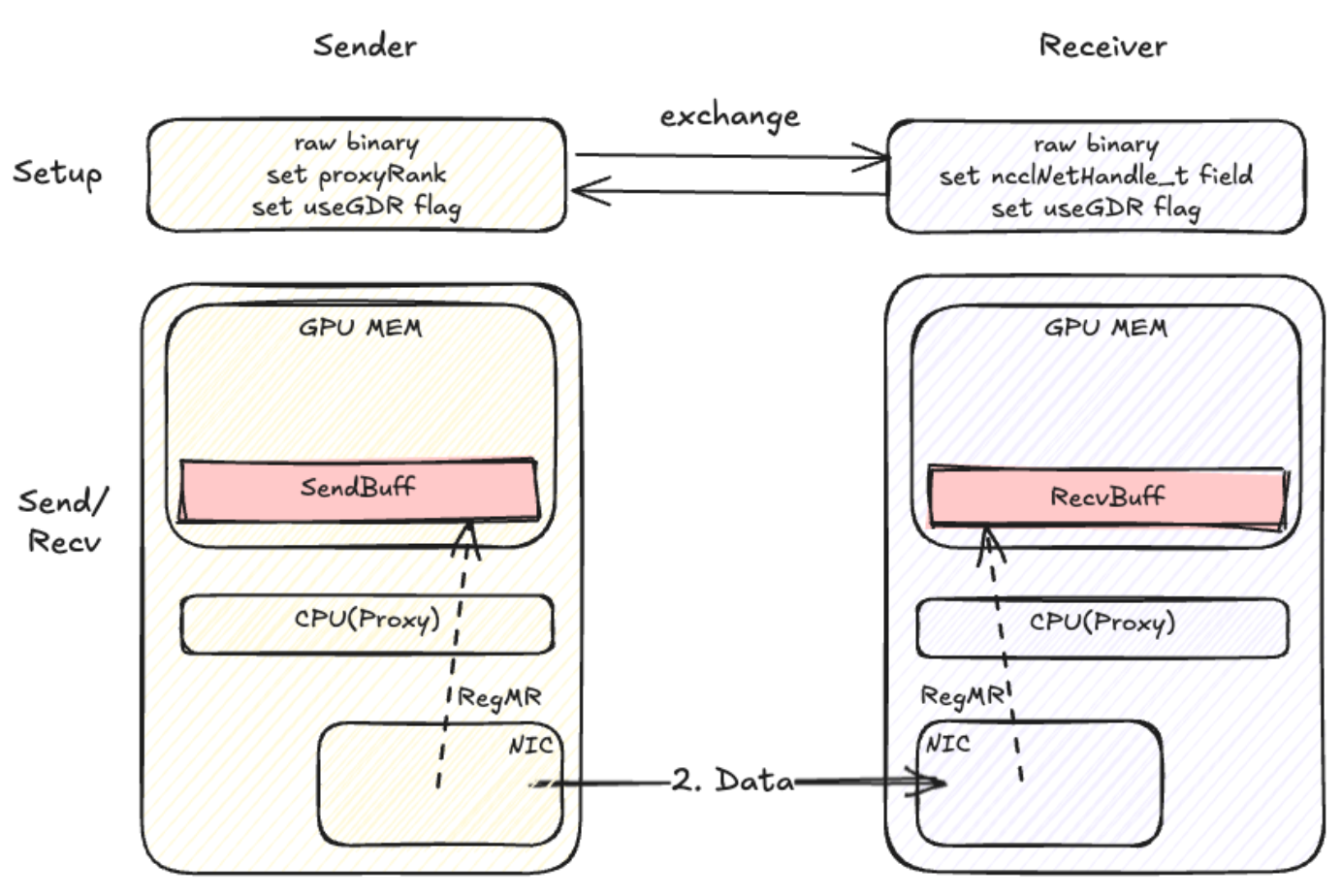
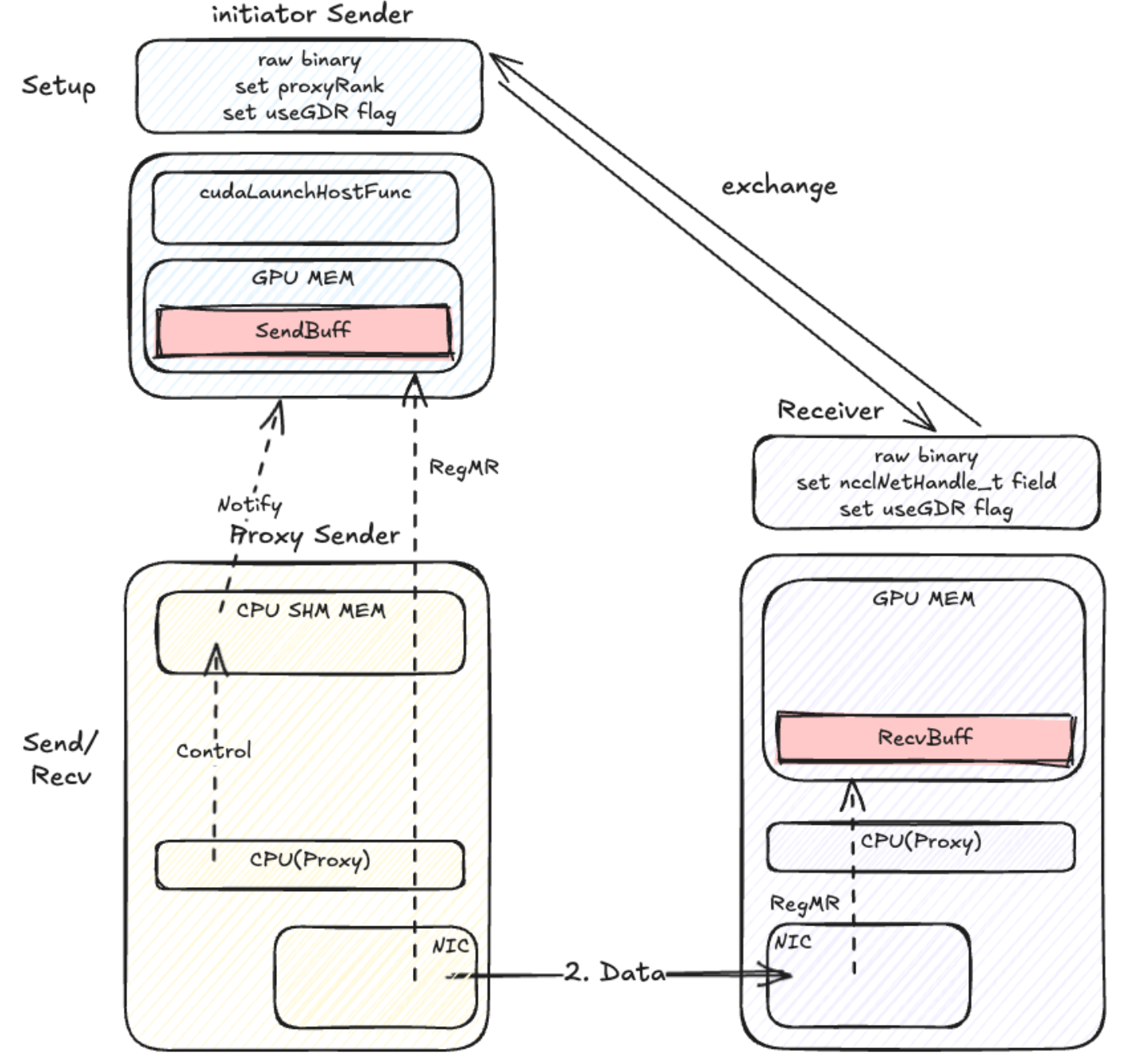
Net Transport with PXN
Origin
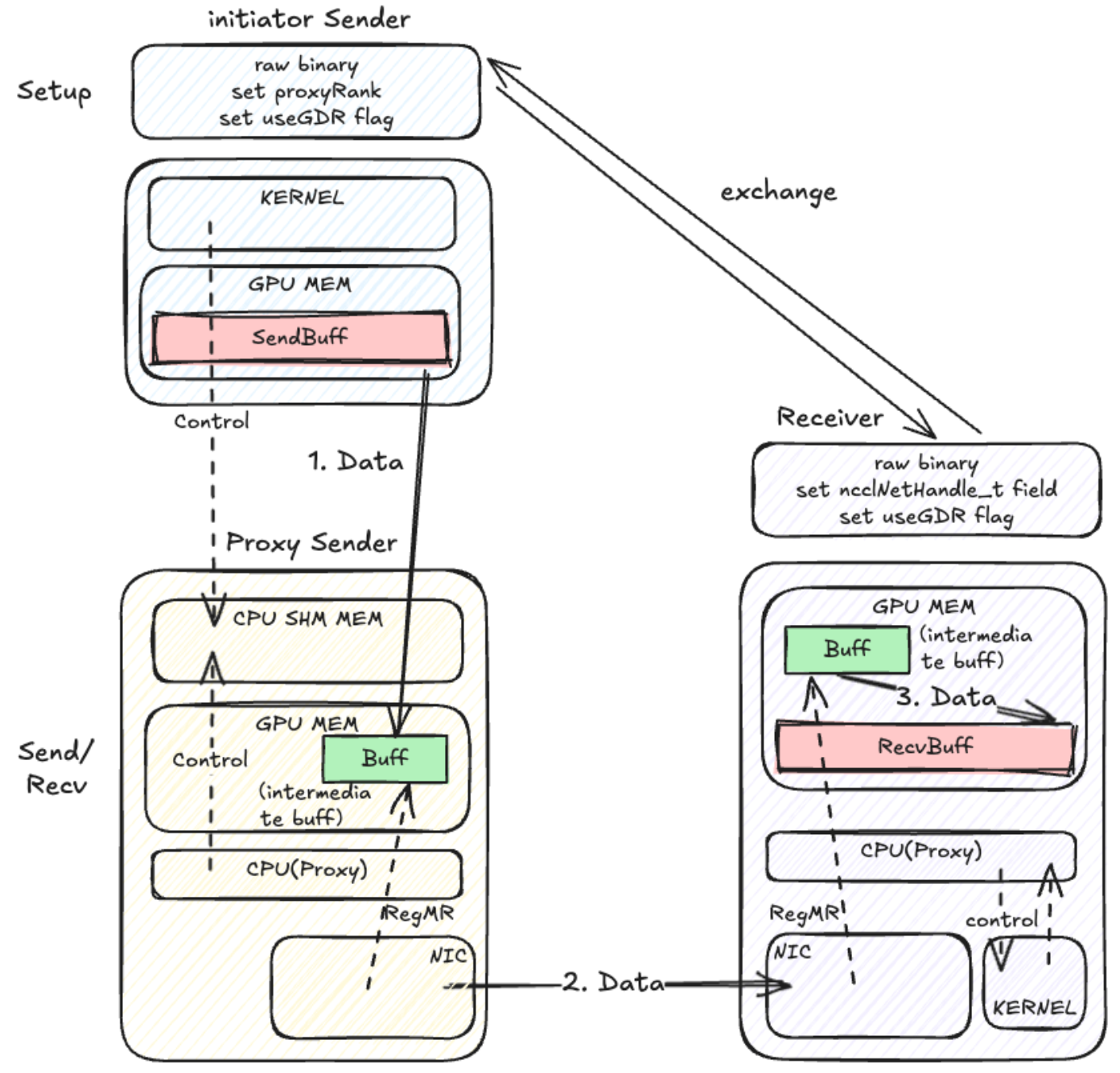 SM-Free with Register buff(Zerocopy)
SM-Free with Register buff(Zerocopy)
P2PTransport
SM-Free
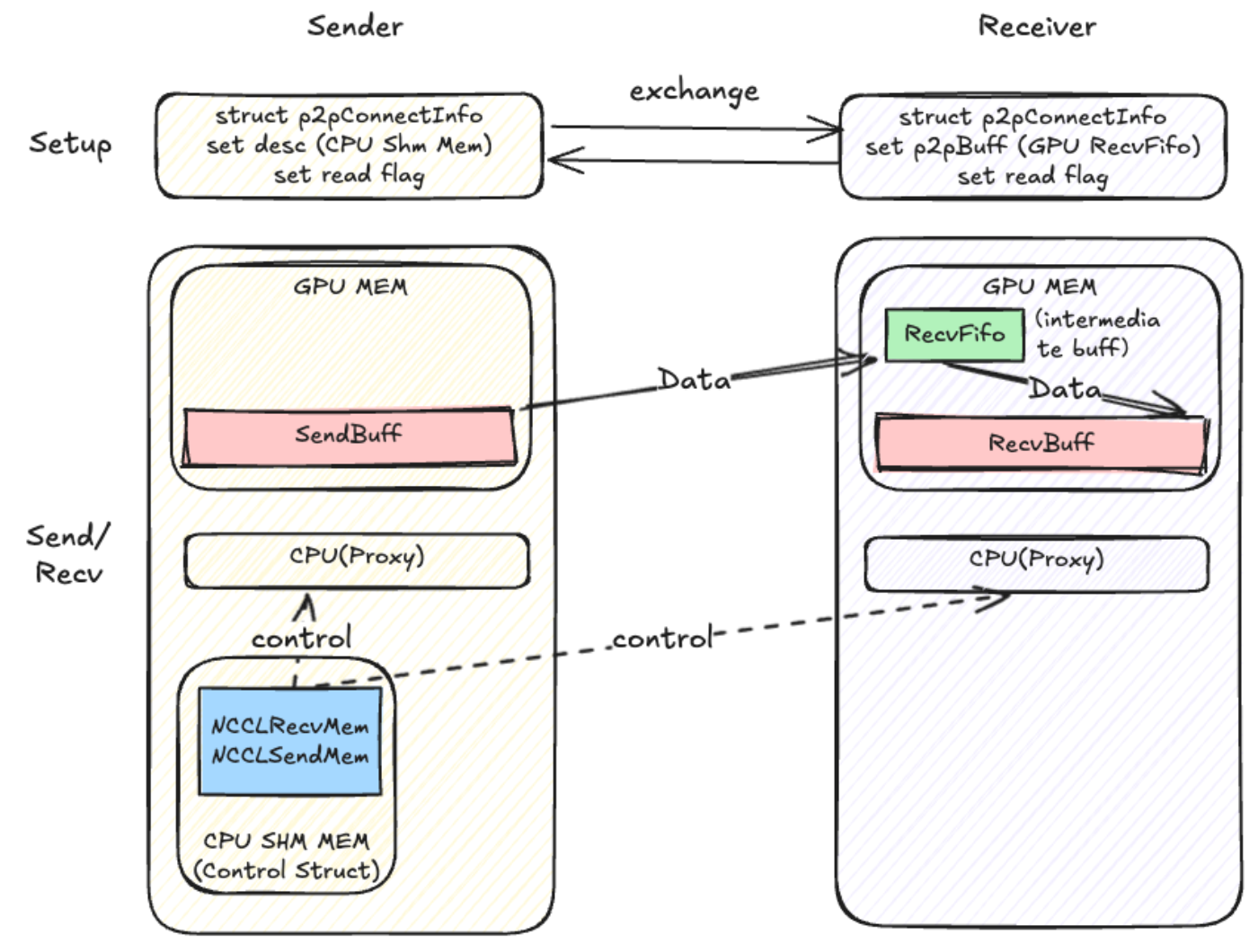
SM-Free with register buff(Zerocopy)