chapter 1. 引言
说了些历史,然后说了CUDA倡导的核心理念:大部分程序都有CPU来执行一部分,需要确保GPU的代码能让CPU的执行起到补充作用,从而充分利用CPU/GPU组合的异构并行能力。
Thus, one must give the CPU a fair chance to perform and make sure that code is written in such a way that GPUs complement CPU execution, thus properly exploiting the heterogeneous parallel computing capabilities of the combined CPU/GPU system. This is precisely what the CUDA programming model promotes.
chapter 2. GPU计算的历史
回顾了GPU计算的历史。首先简要概述图形硬件朝着更高可编程性的演进,然后讨论历史上的通用图形处理器(GPGPU)运动。CUDA GPU当前的许多特性和局限性都源于这些历史发展。
chapter 3. CUDA简介
3.1 data parallelism
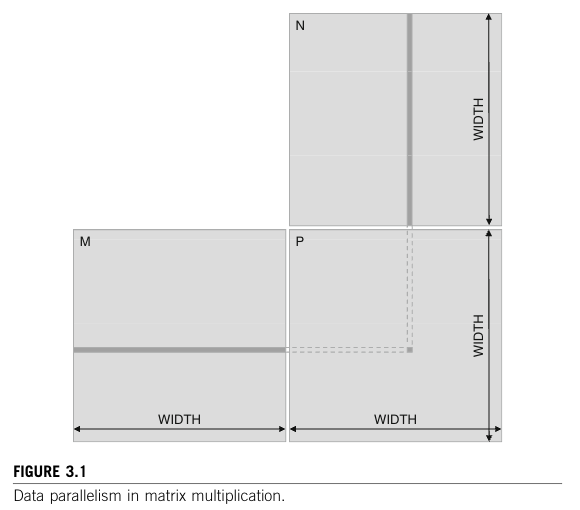
如下例子:M x N = P的矩阵乘法,假设是1000×1000的矩阵乘法。那么就有1,000,000个独立的点积,每个点积都涉及1000次乘法和1000次累加算术运算。因此,大维度的矩阵乘法可以有非常大量的数据并行性。通过并行执行许多点积,CUDA设备可以显著加快矩阵乘法相对于传统主机CPU的执行速度。实际应用中的数据并行性并不总是像我们的矩阵乘法示例中那样简单。在后面的章节中,我们将讨论这些更复杂的数据并行形式。
3.2 cuda program structure
一个cuda程序会有多个stage,可以在cpu、gpu上执行。涉及并行度高的阶段在gpu上执行,但是他们是一个统一的源代码(包含host和device的代码)。NVCC编译器会在compile的时候,将host和device的代码分开。相同的是都是标准的ANSI C代码,但是不同就在于:
- host code由standard c compiler编译,并作为普通CPU进程进行。
- device code由nvcc编译,但是其拓展了labeling data-parallel functions(called kernels)及相关数据结构的关键字,在GPU设备上执行。
kernel会生成很多thread来利用数据并行性,在矩阵乘法示例中,整个矩阵乘法计算可以实现为一个内核,其中每个线程用于计算输出矩阵P的一个元素。在此示例中,内核使用的线程数量是矩阵维度的函数。对于1000×1000的矩阵乘法,将生成1,000,000个线程,计算一个P元素用一个thread。值得注意的是,CUDA线程的开销比CPU线程小得多。CUDA程序员可以假定,由于有高效的硬件支持,生成和调度这些线程只需很少的周期。这与CPU线程形成对比,CPU线程通常需要数千个时钟周期来生成和调度。
CUDA程序的执行过程如图3.2:
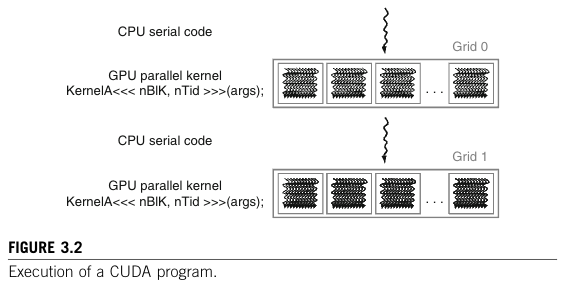
执行从主机(CPU)执行开始。当一个内核函数被调用或启动时,执行转移到设备(GPU),在那里会生成大量线程以利用丰富的数据并行性。在内核调用期间由内核生成的所有线程统称为一个网格(一个网格就是图中的)。图3.2展示了两个线程网格的执行情况。我们很快会讨论这些网格是如何组织的。当一个内核的所有线程完成执行后,相应的网格终止,执行继续在主机上进行,直到调用另一个内核。
3.3 Matrix–Matrix Multiplication Example
在之前的Fortran语言里面,矩阵会按照列优先存储。c语言内是行优先。
 简单来说,cpu完成矩阵乘法(M x N = P)就需要3个for loop。第一个loop是M矩阵的行索引i,第二个loop是N矩阵的列索引j,第三个loop则是在行上的第k个元素(也是在列上的第k个元素)。拿到这三个索引之后,行上的k个元素和列上的k个元素做点积,得到P矩阵的每个元素。
现在这个基础的矩阵乘法要在gpu上实现就会多出几步:
简单来说,cpu完成矩阵乘法(M x N = P)就需要3个for loop。第一个loop是M矩阵的行索引i,第二个loop是N矩阵的列索引j,第三个loop则是在行上的第k个元素(也是在列上的第k个元素)。拿到这三个索引之后,行上的k个元素和列上的k个元素做点积,得到P矩阵的每个元素。
现在这个基础的矩阵乘法要在gpu上实现就会多出几步:
- 把M和N矩阵用cudaMemcpyHost2Device传到gpu内cudaMalloc出来的设备内存上
- 用cuda core计算
- 算完的device侧的结果用cudaMemcpyDevice2Host传回cpu
- free和cudaFree资源
3.4 Device Memories and Data Transfer
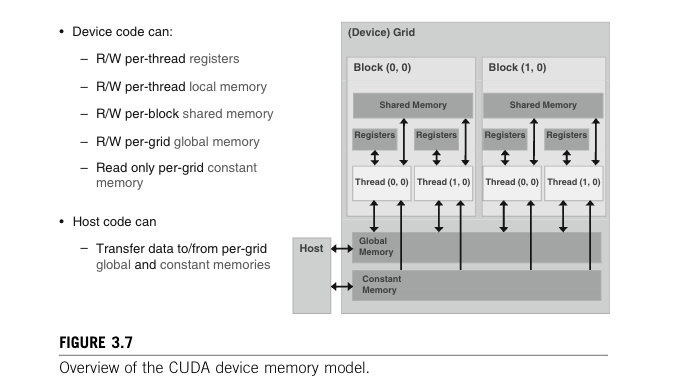
CPU和GPU的内存分别是Host和Device内存。显卡上一般会搭配Dynamic Random Access Memory(DRAM),在设备上要执行你的cuda算子那么就需要在device上先allocate一块设备内存,相关数据从host memory传输到这块device memory,计算后的结果要从这个device memory拷贝回你的host memory。
上述的过程可以分为两个视角,host可以操作的memory和device可以操作的memory。在一个图内看就是:
3.5 Kernel Functions and Threading
前面的铺垫是,我现在device侧用cudaMalloc开辟了device的memory,然后从cpu(Host)通过 cudaMemcpyHost2Device 拿到了数据。现在就到了写kernel的阶段;
kernel就是个内核函数,CUDA用了三个keywords告诉编译器现在device侧kernel的权限等级。
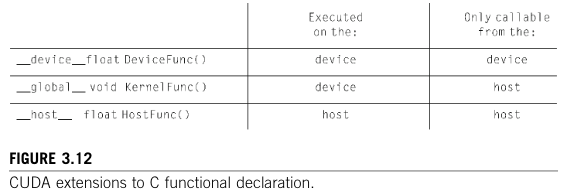 这些关键字的含义。device__关键字表示正在声明的函数是一个CUDA设备函数。设备函数在CUDA设备上执行,并且只能从内核函数或另一个设备函数中调用。设备函数既不能有递归函数调用,也不能通过指针进行间接函数调用。host__关键字表示正在声明的函数是一个CUDA主机函数。主机函数只是一个传统的C函数,它在主机上执行,并且只能从另一个主机函数中调用。默认情况下,如果CUDA程序中的所有函数在声明中没有任何CUDA关键字,那么它们都是主机函数。这是合理的,因为许多CUDA应用程序是从仅支持CPU执行的环境移植过来的。程序员会添加内核函数和设备函数。
请注意,在函数声明中可以同时使用__host__和__device__。这种组合会促使编译系统为同一个函数生成两个版本。一个版本在主机上执行,并且只能从主机函数中调用。另一个版本在设备上执行,并且只能从设备函数或内核函数中调用。当相同的函数源代码可以简单地重新编译以生成设备版本时,这就支持了一种常见的用法。许多用户库函数可能都属于这一类。
矩阵的最基础的kernel实现如下:
这些关键字的含义。device__关键字表示正在声明的函数是一个CUDA设备函数。设备函数在CUDA设备上执行,并且只能从内核函数或另一个设备函数中调用。设备函数既不能有递归函数调用,也不能通过指针进行间接函数调用。host__关键字表示正在声明的函数是一个CUDA主机函数。主机函数只是一个传统的C函数,它在主机上执行,并且只能从另一个主机函数中调用。默认情况下,如果CUDA程序中的所有函数在声明中没有任何CUDA关键字,那么它们都是主机函数。这是合理的,因为许多CUDA应用程序是从仅支持CPU执行的环境移植过来的。程序员会添加内核函数和设备函数。
请注意,在函数声明中可以同时使用__host__和__device__。这种组合会促使编译系统为同一个函数生成两个版本。一个版本在主机上执行,并且只能从主机函数中调用。另一个版本在设备上执行,并且只能从设备函数或内核函数中调用。当相同的函数源代码可以简单地重新编译以生成设备版本时,这就支持了一种常见的用法。许多用户库函数可能都属于这一类。
矩阵的最基础的kernel实现如下:
__global__ void Matmul_kernel(float* M_device, float* N_device, float* P_device, int width)
{
int ix = blockIdx.x * blockDim.x + threadIdx.x;
int iy = blockIdx.y * blockDim.y + threadIdx.y;
int idx = iy * width + ix;
float P_element = 0;
for (int k = 0; k < width; k ++){
float M_element = M_device[iy * width + k];
float N_element = N_device[k * width + ix];
P_element += M_element * N_element;
}
P_device[idx] = P_element;
}这里还存在其他的keywords,比如threadIdx。gpu中所有的线程是执行相同的内核代码,现在每个线程要去指定的内存地址上取数据。所以这个threadIdx:
- 是一个结构体,包含
.x,.y,.z,用于描述线程在 block 中的位置(最多三维)。 - 它标识了预定义的变量,这个变量值在 运行时由 GPU 硬件 register 提供。
- GPU调度的时候会给每个线程分配一组专属的register,再里面又包括
threadIdx、blockIdx等坐标值、要处理的寄存器变量。 例如,这里每个线程的i是不同的,所以就可以取到不同的input执行相同的计算,实现并行。
int i = threadIdx.x
output[i]=input[i] * 2;这里launch这个Matmul_kernel需要至少指定2个参数如下:
dim3 dimBlock(blocksize, blocksize);
dim3 dimGrid(width / blocksize, width / blocksize);
Matmul_kernel<<<dimGrid, dimBlock, 0, nullptr>>>(M_device, N_device, P_device, width);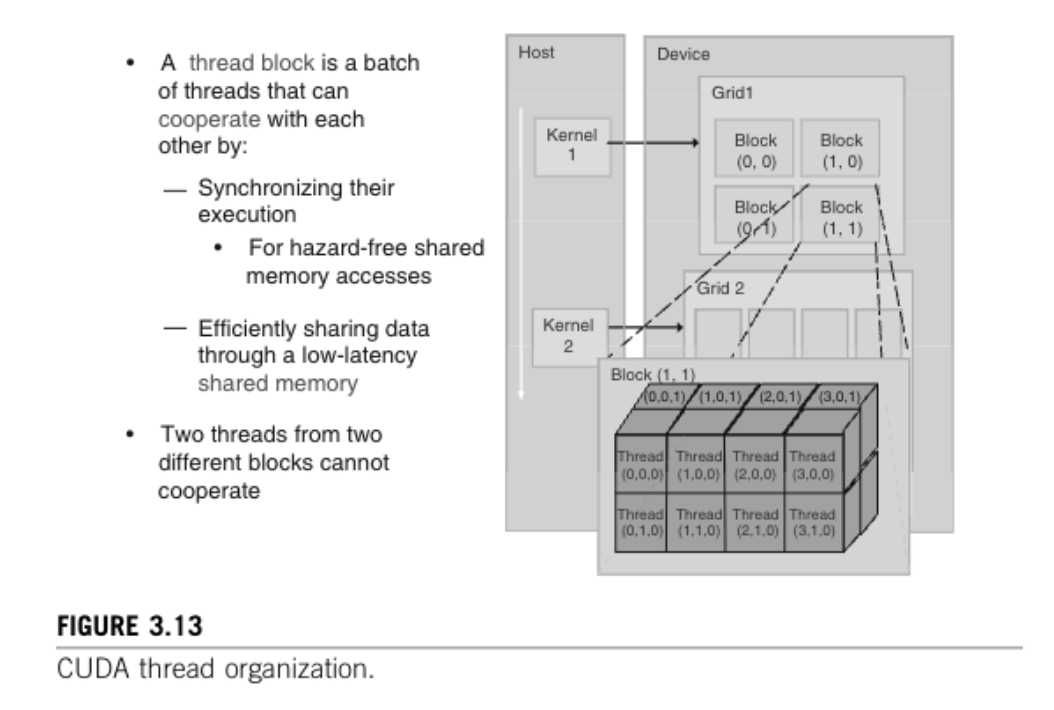 线程在网格中按两级层次结构进行组织,如图3.13所示。为简化起见,图3.13中仅展示了少量线程。实际上,一个网格通常会包含更多的线程。在顶层,每个网格由一个或多个线程块组成。网格中的所有线程块具有相同数量的线程。在图3.13中,网格1被组织为一个2×2的4个线程块的阵列。每个线程块都有一个由CUDA特定关键字blockIdx.x和blockIdx.y给出的唯一二维坐标。所有线程块必须以相同的方式组织相同数量的线程。
线程在网格中按两级层次结构进行组织,如图3.13所示。为简化起见,图3.13中仅展示了少量线程。实际上,一个网格通常会包含更多的线程。在顶层,每个网格由一个或多个线程块组成。网格中的所有线程块具有相同数量的线程。在图3.13中,网格1被组织为一个2×2的4个线程块的阵列。每个线程块都有一个由CUDA特定关键字blockIdx.x和blockIdx.y给出的唯一二维坐标。所有线程块必须以相同的方式组织相同数量的线程。
3.6 Summary
本章旨在快速概述CUDA编程模型。所讨论的扩展内容总结如下:
3.6.1 Function Declarations
CUDA扩展了C函数声明语法,以支持异构并行计算。这些扩展总结在图3.12中。通过使用__global__、device__或__host__中的一个,CUDA程序员可以指示编译器生成内核函数、设备函数或主机函数。如果在函数声明中同时使用__host__和__device,编译器会生成该函数的两个版本,一个用于设备,一个用于主机。 如果函数声明没有任何CUDA扩展关键字,该函数默认为主机函数。
3.6.2 内核启动
CUDA通过在<<<和>>>之间包围内核执行配置参数,扩展了C函数调用语法。这些执行配置参数仅在调用内核函数(即内核启动)时使用。
3.6.3 预定义变量
CUDA内核可以访问一组预定义变量,这些变量允许每个线程相互区分,并确定每个线程要处理的数据区域。我们在本章中讨论了 threadIdx 变量。在第4章中,我们将进一步讨论 blockIdx、gridDim 以及 blockDim 。
请注意,
gridDim和blockDim变量是内置的预定义变量,在内核函数中可以访问。不应将它们与用户定义的dimGrid和dimBlock变量混淆,后者在主机代码中用于设置配置参数。一旦内核启动,这些配置参数的值最终将成为gridDim和blockDim的值。
da